银河通用重磅发布全球首个端到端具身抓取基础大模型 GraspVLA,定义全合成大数据预训练新范式!
发布时间:2025-01-181月9日,银河通用联合北京智源人工智能研究院、北京大学和香港大学,发布全球首个全面泛化的端到端具身抓取基础大模型 GraspVLA。
该模型通过合成大数据进行预训练,训练数据达到十亿级的“视觉-语言-动作”对,从而实现了泛化闭环抓取能力,并在光照、背景、平面位置、空间高度、动作策略、动态干扰和物体类别等七大泛化能力上表现出色。该模型展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
训练过程
GraspVLA 的训练包含预训练和后训练两部分。预训练完全基于合成大数据,训练数据达十亿帧「视觉-语言-动作」对,掌握泛化闭环抓取能力、达成基础模型,可在千变万化的真实场景中零样本测试,并展现出七大泛化能力;后训练针对特别需求,用小样本学习迁移基础能力到特定场景,维持高泛化性的同时形成符合产品需求的专业技能。
七大泛化能力
GraspVLA团队总结的具身基础模型七大泛化金标准包括:光照泛化、背景泛化、平面位置泛化、空间高度泛化、动作策略泛化、动态干扰泛化、物体类别泛化。
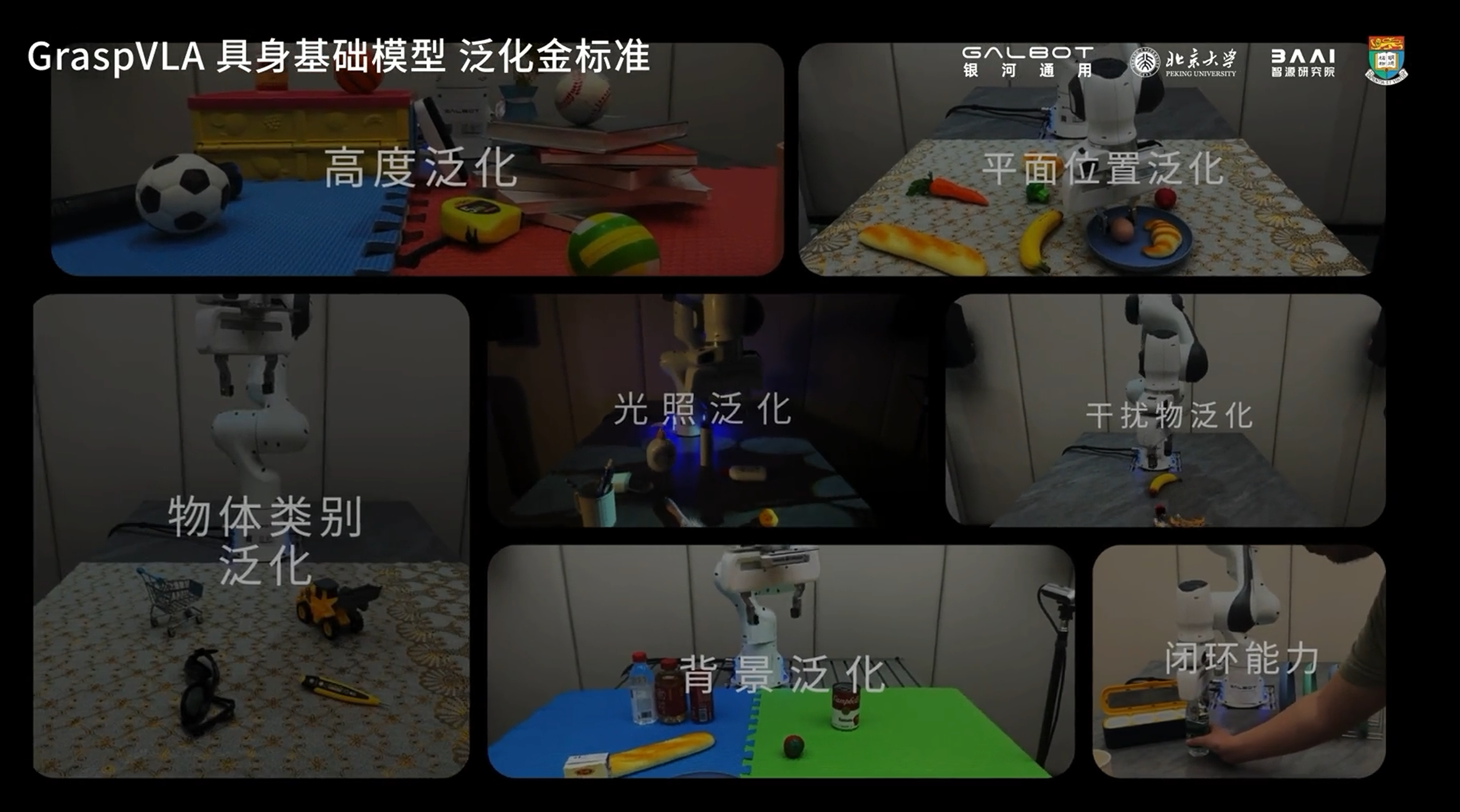
01 光照泛化:光影百变,能力不变
咖啡厅、便利店、生产车间、KTV等真实工作环境中的光照条件各异,光线的冷暖、强弱变化不尽相同,既有渐变也有骤变。面对以上各种情景,GraspVLA都不出意外,表现稳定:

视频为二倍速播放
甚至是在极端黑暗环境下移动目标物体,GraspVLA 也能准确找到并正常抓取:

视频为二倍速播放
02 背景泛化:万千纹理,始终如一
实际环境中机器人工作场景不尽相同,面对不同材质、不同纹理的桌面和操作台,甚至动态变化的背景画面,GraspVLA皆不受影响,稳稳出手:

视频为三倍速播放
同样的,面对动态变化的背景画面,GraspVLA 亦不受影响(需要注意的是,GraspVLA 采用双相机视角作为输入,演示视频拍摄的视角对应了机器人正面的相机视角):

视频为三倍速播放
03 平面位置泛化:平移旋转,随机应变
将物体在桌面上随意平移、旋转,GraspVLA仍旧轻车熟路:

视频为二倍速播放
04 空间高度泛化:高低错落,从容不迫
GraspVLA具备强大的高度泛化能力,即便是面对物体摆放高低错落的工作台,用户也不用担心模型蒙圈:

视频为二倍速播放
05 动作策略泛化:闭环调整,随心应对
GraspVLA 实时进行推理决策,不仅会移动跟随目标,对于物体竖放、倒放等不同摆放方式,还可根据物体和夹爪的位姿自动调整策略,选择最安全合理的抓取方式,处理复杂情况得心应手:

06 动态干扰泛化:超强抗扰,稳定抓取
真实工作场景复杂多变,机器人在执行任务时常常会受到干扰。在工作过程中,即使往工作空间中随意添加干扰物体,甚至发生撞击并使目标物体随机移位,GraspVLA 依然能够稳定地完成任务:

视频为二倍速播放
07 物体类别泛化:开放词汇,触类旁通
上述测试中,所有物体、场景、摆放方式均未进行任何训练,GraspVLA 仅通过仿真合成数据学习到的语义和动作能力,实现了在真实世界中零样本泛化测试。
此外,通过把仿真合成的动作数据和海量互联网语义数据巧妙地联合训练,对于没有学习过动作数据的物体类别,GraspVLA 也能把已掌握的动作能力泛化迁移:


视频为三倍速播放
后训练应用场景与效果
对于有些特殊需求,后训练展示出快速适应及迁移能力。
01 迅速服从指定规范并“举一反三”:商超场景中,仅需采集少量(少于一个人遥操一天)真实数据,就能让 GraspVLA 理解并满足按顺序抓取指定商品的需求,并能举一反三,将这种少样本习得的行为自动迁移到其他品牌的同类商品。
02 迅速掌握新词汇,拓展新类别:工业场景中,仅需采集少量轨迹进行快速后训练,GraspVLA 就能迅速掌握特殊工业名词,并从任意摆放的密集场景中精准找出对应零件。
03 迅速对齐人类偏好:家庭场景中,通过采集少量带偏好的抓取轨迹,GraspVLA 即可学会按照自然语义抓取。
VLA新范式的现在雨将来
VLA以仿真合成大数据预训练为核心,突破了全球范围内具身通用机器人数据采集昂贵、泛化性不足的瓶颈,具有低成本、大数据、高泛化特点,具有重要的里程碑意义,并将在 2025 年引领端到端具身大模型走向规模商业化!
https://mp.weixin.qq.com/s/kFHggswjt8z9xHp_3Hg2IQ
来源:银河通用机器人
