李飞飞团队新作:让机器人更懂家务!(附开源代码)
发布时间:2024-10-16最近,斯坦福大学李飞飞教授的研究团队让家务机器人玩出了新花样!
能够灵活自如地倒茶、叠衣服、整理书籍、扔垃圾:

要知道今年三月份的时候,他们的家务机器人还只能简单地擦个桌子,切个水果:
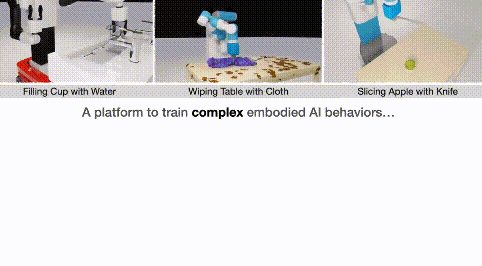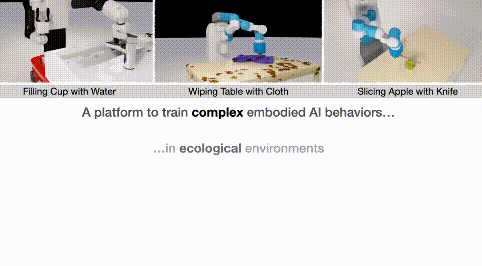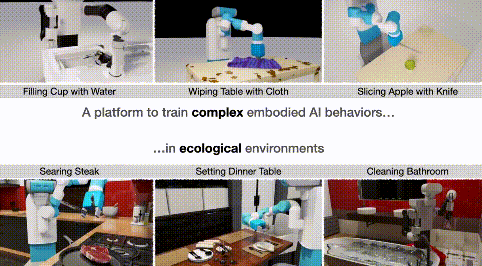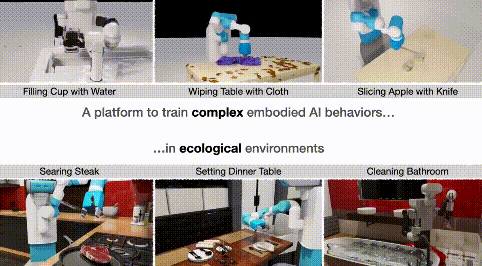
而仅过了半年,机器人就能如此流畅地自学家务,做得有模有样了:

这源于他们发明的一种叫ReKep的黑科技,ReKep让机器人学会了"看重点"做家务。它把复杂动作拆解成简单步骤,并标记出关键点。
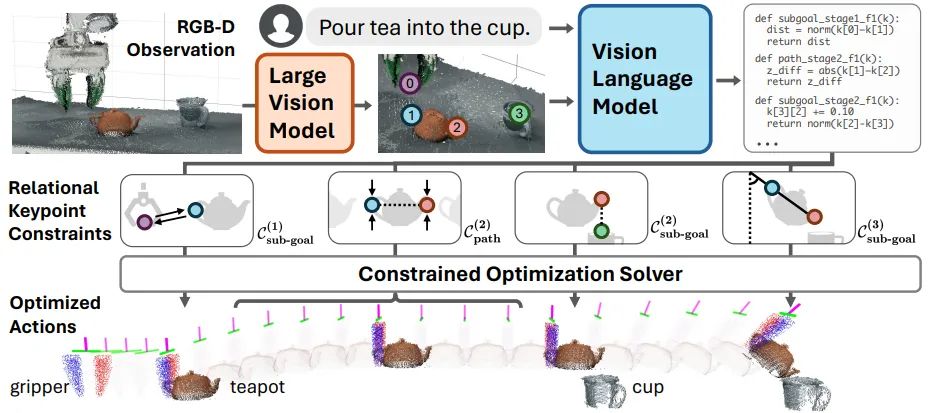
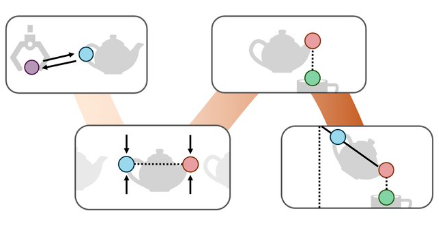
以倒茶为例,机器人先用摄像头找到茶具位置,然后识别茶壶把手、壶嘴、杯口等关键点。
ReKep会告诉机器人这些点之间该保持什么关系,比如怎么拿壶、倾倒角度和力度等。机器人按这些规则行动就能漂亮地完成任务。
更厉害的是,机器人还能自主学习。它会记住哪些动作效果好,不断改进自己的"倒茶技能"。这种方法很灵活,换了新茶具机器人也能应对自如。



目前,关于 ReKep 技术的论文已在 arXiv 公开,代码已开源。
论文标题:ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
论文地址:https://arxiv.org/pdf/2409.01652
项目网站:https://rekep-robot.github.io/
项目代码:github.com/huangwl18/ReKep
下面让我们再深入了解一下ReKep是如何工作的~
关系关键点约束:灵活而高效的任务表示
传统的机器人操作方法通常依赖于预定义的物体模型和严格的任务规划,难以适应复杂多变的现实环境。ReKep提出了一种新的思路 - 用一系列关键点之间的约束关系来描述任务目标和过程。
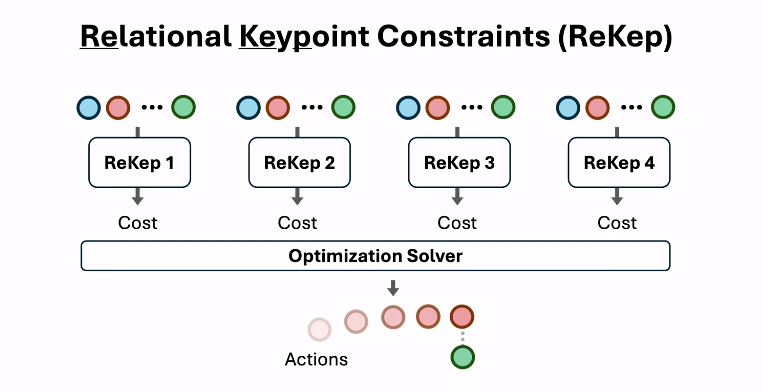
具体来说,ReKep将每个操作任务分解为多个阶段,每个阶段包含两类约束:
子目标约束:描述该阶段结束时需要满足的关键点关系
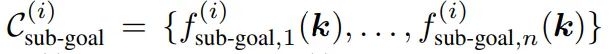
路径约束:描述该阶段执行过程中需要持续满足的关键点关系
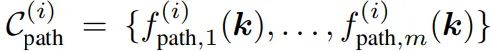
这些约束被表示为Python函数,输入是一组3D关键点的坐标,输出是一个数值成本。约束满足时,成本应该小于等于0。
举个例子,倒茶这个任务可以分为三个阶段:抓握、对准、倾倒。第一阶段的子目标约束可能是"机器人末端执行器应该靠近茶壶把手"。第二阶段的路径约束可能是"茶壶应该保持直立,避免溢出",而子目标约束是"茶壶嘴应该在杯口上方"。第三阶段的子目标约束则可能指定倾倒的角度。
这种表示方法非常灵活,可以描述各种复杂的空间和时序关系,适用于多阶段、实际场景、双臂协调、动态响应等各种类型的任务。同时,由于约束是以Python函数的形式给出,可以直接被优化求解器使用,从而高效地生成机器人动作。
优化求解:从约束到动作的桥梁
有了ReKep约束,如何生成具体的机器人动作呢?研究人员采用了一种分层优化的方法。
首先,对于每个阶段,求解一个"子目标问题",得到该阶段结束时机器人末端执行器应该达到的位姿。这个优化问题的目标是满足子目标约束,同时考虑一些辅助成本,如避免碰撞、保证可达性等。
然后,求解一个"路径问题",规划从当前位置到子目标位置的轨迹。这个优化问题的目标是满足路径约束,同时最小化路径长度、避免碰撞等。
这两个优化问题被反复求解,形成一个滚动时域的控制过程。研究人员使用SciPy库实现了求解器,通过精心的问题分解和算法设计,使得系统能够以约10Hz的频率实时运行,快速响应环境变化。
此外,系统还具备"回溯"能力。如果检测到之前阶段的约束被违反(比如茶杯被拿走),就会自动回到前一个阶段重新规划。这使得机器人能够灵活应对各种意外情况。
自动生成:视觉智能赋能任务规划
ReKep最独特的优势在于,它可以借助大型视觉模型和视觉语言模型,从RGB-D观察和自然语言指令自动生成约束,无需人工标注。
具体来说,系统首先使用DINOv2模型从图像中提取有意义的关键点候选。然后,将标注了关键点的图像和语言指令输入GPT-4v模型,生成一系列Python函数形式的ReKep约束。
这个过程可以看作是用代码(GPT-4v支持的输出模态)来表达细粒度的空间关系,这些关系往往难以用自然语言准确描述。比如,"把茶壶倾斜到45度"这样的指令,通过视觉参考就能被准确地转化为关键点之间的几何关系。

这种方法极大地提高了系统的通用性和可扩展性。它可以处理各种新颖的任务和环境,而无需针对每个任务进行专门的数据收集或模型训练。同时,由于约束是以代码形式给出,它们可以被直接用于优化求解,形成了从高层指令到底层控制的端到端pipeline。
总的来说,ReKep巧妙地结合了约束优化的高效性、关键点表示的灵活性,以及大型模型的通用性,为机器人操作开辟了一条新的道路。研究人员在轮式单臂和固定式双臂平台上进行了实验,展示了系统在多阶段、实际场景、双臂协调、人机协作等各种任务中的出色表现。
这项工作为未来更加智能、灵活的机器人系统指明了方向。随着视觉和语言模型的进一步发展,我们可以期待看到能够理解更复杂指令、适应更多样环境的机器人助手,为人类的工作和生活带来便利。
来源:机器人大讲堂
