英伟达开源“巨无霸”系列模型:3400亿参数、性能对标GPT-4o
发布时间:2024-06-19当地时间6月14日,英伟达宣布开源Nemotron-4 340B(3400亿参数)系列模型——包括基础模型Base、指令模型Instruct和奖励模型Reward,并构建了一个高质量合成数据生成的完整流程。

官方介绍称,开发者可使用Nemotron-4 340B系列模型生成合成数据,用于训练大型语言模型(LLM),以及用于医疗保健、金融、制造、零售和其他行业的商业应用。
从这方面来看,Nemotron-4 340B是一系列具有开创意义的开源模型,有可能彻底改变训练LLM的合成数据生成方式。从此,各行各业都无需依赖大量昂贵的真实世界数据集了,用合成数据就可以创建性能强大的特定领域大语言模型。
根据英伟达公布的测试结果,Nemotron-4 340B已超越Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4一较高下。
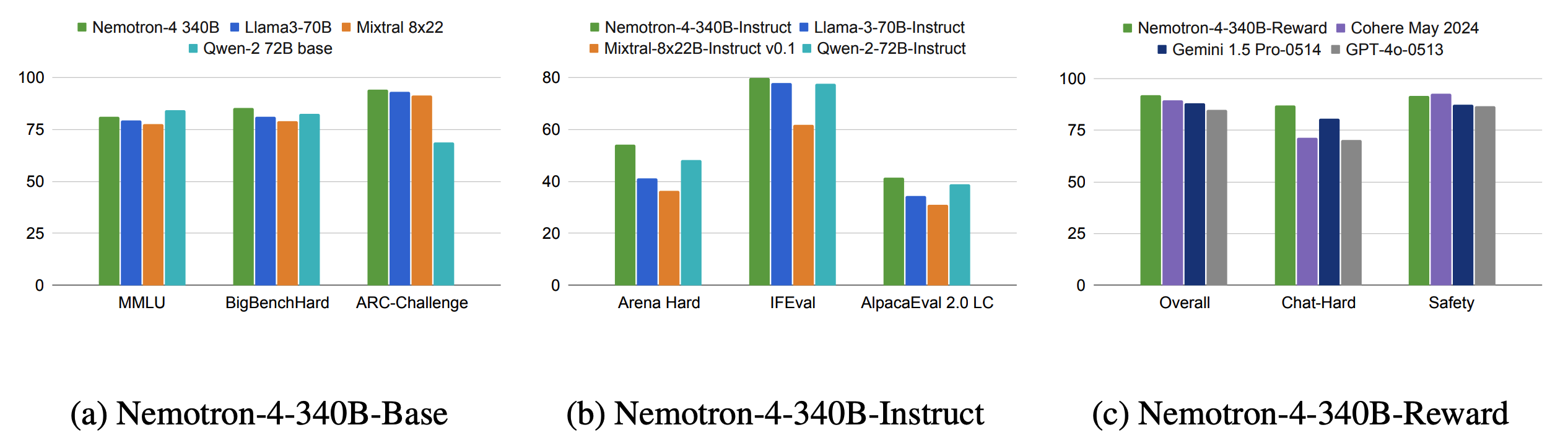
Nemotron-4 340B系列模型支持4K上下文窗口、50多种自然语言和40多种编程语言,训练数据截止到2023年6月。训练数据方面,英伟达采用了高达9万亿个token。其中,8万亿用于预训练,1万亿用于继续训练以提高质量。
值得一提的是,在模型对齐过程中,超过 98% 的数据都是合成的,这展示了这些模型在生成合成数据方面的有效性。
英伟达表示,这些模型在各种评估基准上的表现与开放访问模型相比具有竞争力,并且在以 FP8 精度部署时,其大小适合配备 8 个 GPU 的单个 DGX H100。
在各种研究和商业应用中,特别是在生成用于训练较小语言模型的合成数据时,社区可以从这些模型中获益。
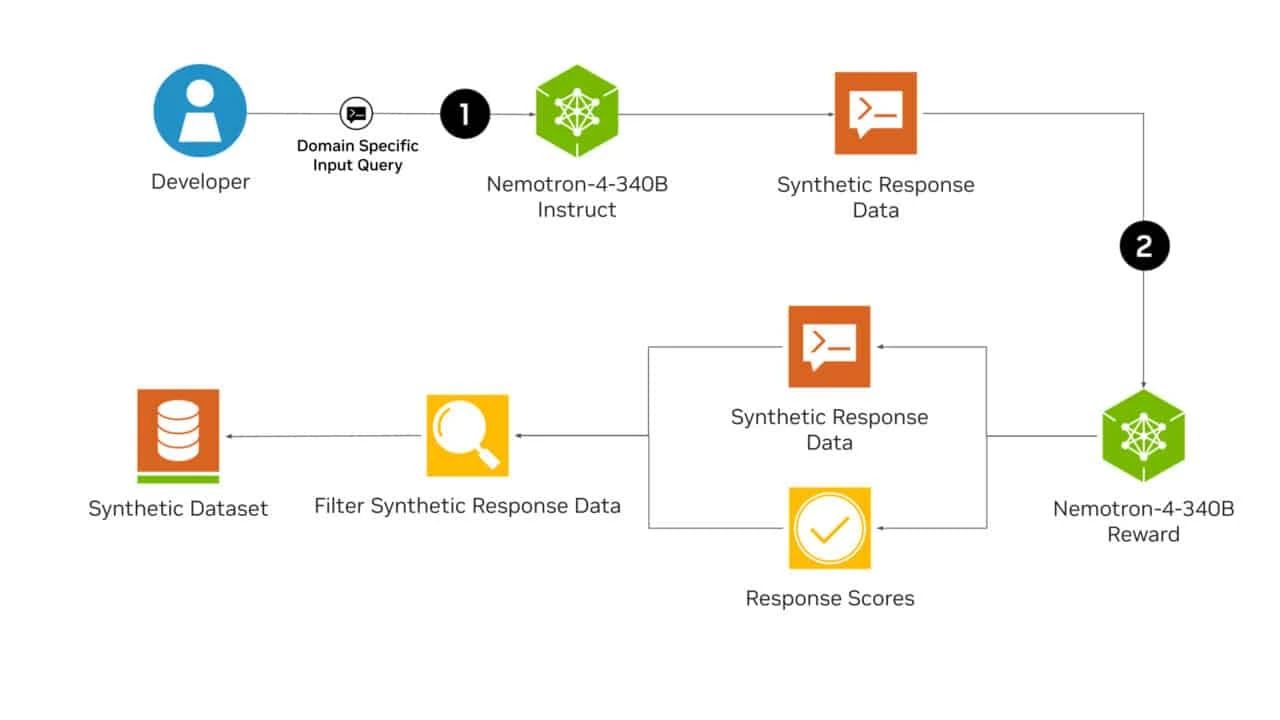
为了进一步支持开放式研究和促进模型开发,英伟达还将开源模型配准过程中使用的合成数据生成管道。
来源:OSC开源社区
