首个AI软件工程师Devin完整技术报告出炉,还有人用GPT做出了「复刻版」
发布时间:2024-03-19近日,Cognition AI 团队发布的首个 AI 软件工程师 Devin,可以帮助工程师完成各种开发任务,只需要人类用户下达指令,Devin就可以自行完成开发、调试、debug、部署等。如果有需要,Devin还可以为用户提供抽样调查报告,满足用户在代码方面的任何要求。
Devin的发布很快引爆了 AI 社区,引发了人们对程序员这个职业未来前景的热议。
在对 Devin 的评估中,团队使用了 SWE-bench。这是一个由 GitHub 问题和拉取请求组成的软件工程系统的自动化基准测试。他们认为 SWE-bench 是一个不错的选择,它确定性地评估(通过单元测试)系统解决现实世界代码库问题的能力,并与 HumanEval 等仅限于独立功能的基准测试不同。
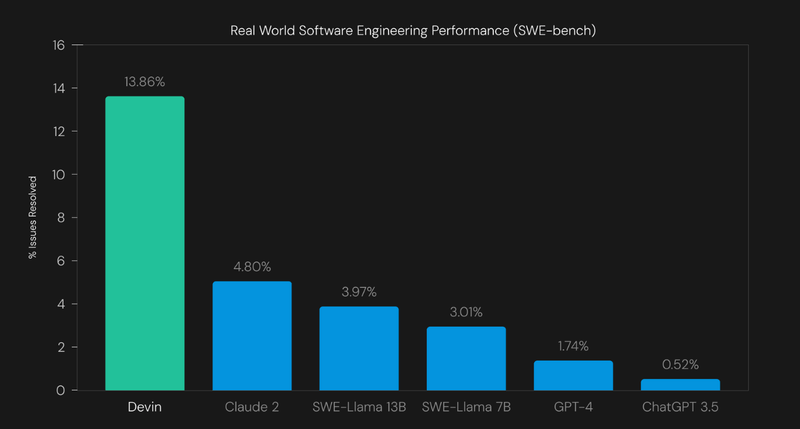
从结果来看,在 SWE-Bench 基础测试中,无需人类辅助,Devin 就可以解决 13.86% 的问题。而当前 SOTA 模型,在没有人类帮忙的情况下,只能完成 1.96% 的问题。即使提供了要编辑(辅助)的确切文件,当前 SOTA 模型也只能解决 4.80% 的问题。
数据集
具体来讲,SWE-bench 是一个包含 2294 个问题和 GitHub 流行开源 Python 存储库中拉取请求(pull request)的数据集,目的是测试系统编写真实代码的能力。
每个 SWE-bench 实例都包含一个 GitHub 问题和解决该问题的拉取请求。拉取请求必须包含一个单元测试,该测试在代码更改之前失效并在代码更改之后通过(称为「未能通过」(fail to pass)测试)。diff 分为两部分,即 patch 和 test_patch,分别包含代码更改和测试更改。
接着要求正在评估的系统根据 GitHub 问题描述和存储库(问题发生时)生成 diff。如果在修补(patch)编辑后所有单元测试都通过,则该示例被认为是成功的。

在 SWE-bench 中,大模型(LLM)要么获得一组正确的文件进行编辑(辅助)或者一个单独的系统根据与问题文本的相似性检索要编辑的文件(无辅助)。作为一个智能体,Devin 不会收到任何文件列表,而是自行导航文件,这与「无辅助」LLM 更具可比性。
正确解决 SWE-bench 示例具有挑战性,更难的 PR 需要更改数十个文件、保持向后兼容性和 / 或进行大量复杂的推理。即使有辅助,最好的 LLM 也只能达到 4.80% 的成功率。
方法
团队采用 SWE-bench 来评估智能体,实现了比 LLM 原始评估更通用的设置。
设置
l 团队使用标准化 prompt 来端到端地运行智能体,要求它仅在给出 GitHub 问题描述的情况下编辑代码。在运行期间,团队不会向智能体提供任何其他用户输入。
l 存储库被克隆到智能体的环境中。团队只在 git 历史记录中保留 base commit 及其 ancestor,以防止信息泄露给智能体。值得注意的是,他们删除了 git Remote,以便 git pull 不起作用。
l 团队在测试开始前搭建了 Python conda 环境。
l 团队将 Devin 的运行时间限制为 45 分钟,因为与大多数智能体不同,它具有无限期运行的能力。如果需要,它可以选择提前终止。
评估
l 一旦智能体运行退出,团队会将所有测试文件重置为原始状态,以防智能体修改测试。他们获取文件系统中的所有其他 diffs 并将它们提取为补丁。
l 为了确定哪些文件是测试文件,团队采用测试补丁中修改的所有文件的集合。
l 团队将智能体的补丁应用到存储库,然后应用测试补丁。
l 团队运行 SWE-bench 提供的 eval 命令并检查是否所有测试都通过。
结果
团队随机选择了 SWE 基准测试集中 25% 的问题(即 2294 个中的 570 个),对 Devin 进行了评估。这样做是为了减少完成基准测试所需的时间。
结果显示,Devin 成功解决了 570 个问题中的 79 个问题,成功率为 13.86%。这甚至比之前 SOTA 大模型(Claude 2)的 4.80% 还要高得多。
下图中的基线在「辅助」设置下进行评估,其中为模型提供需要编辑的确切文件。基线在「无辅助」设置下表现较差,其中单独的检索系统选择 LLM 编辑的文件,最佳的模型是 Claude 2 + BM25 检索,成功率为 1.96%。
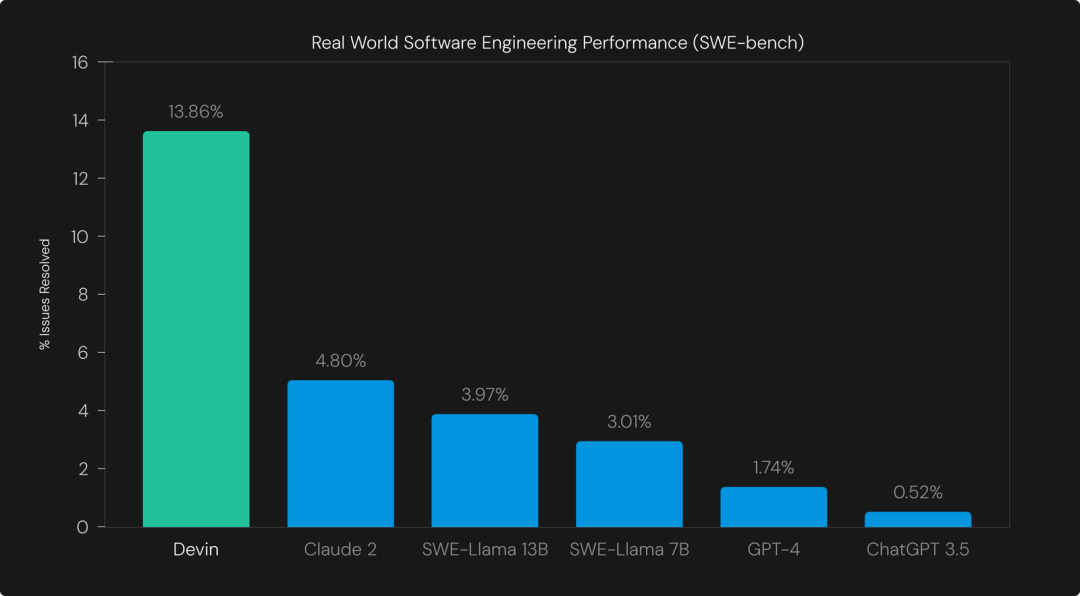
不过团队表示,辅助或无辅助设置下,其他模型都不能与 Devin 进行严格比较。Devin 获得整个存储库并可以自由浏览文件,因此他们选择更强的数字进行基线比较。团队认为,端到端运行智能体对于 SWE-bench 来说是更自然的设置,这样更类似于现实世界的软件开发。
分析
多步规划
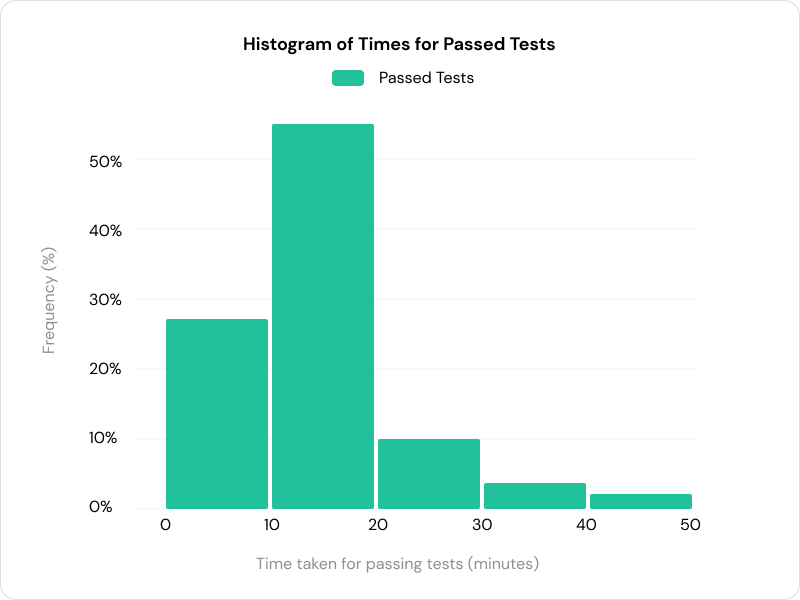
Devin 可以执行多步规划来接收来自环境的反馈。72% 的通过测试需要 10 分钟以上才能完成,这表明迭代能力有助于 Devin 取得成功。
定性案例
团队对 Devin 的进行了一些定性分析。这里 Devin 仅获得了问题描述和克隆存储库作为输入。
示例 1:✅ scikit-learn__scikit-learn-10870
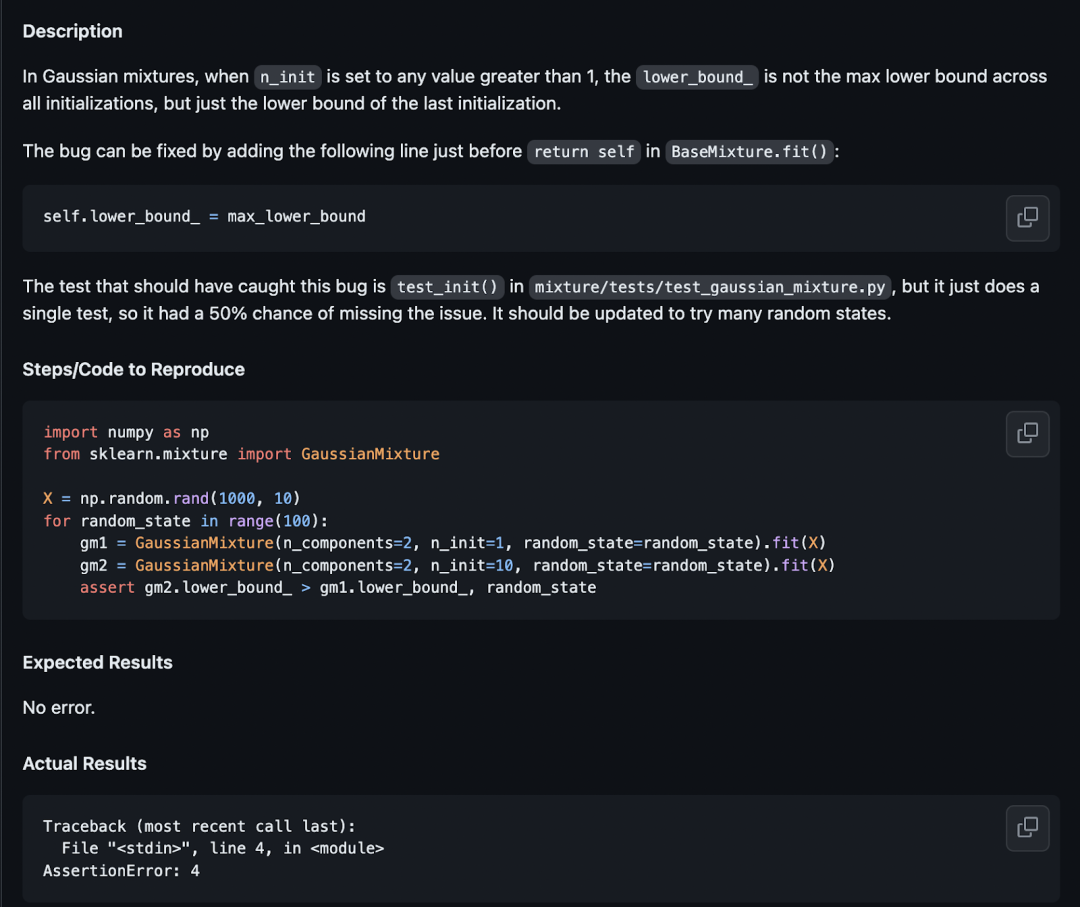
Devin 最初对描述感到困惑,并按照描述在 return self 之前添加 self.lower_bound_ = max_lower_bound before return self 。这实际上不正确,因为该变量尚未定义。
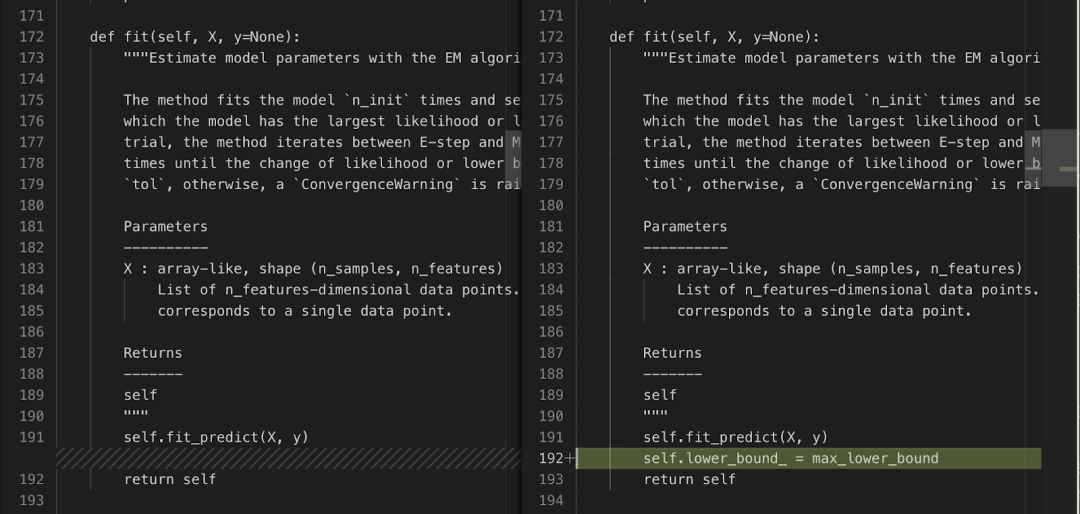
随后,Devin 根据问题描述中提供的测试代码,更新了测试文件。
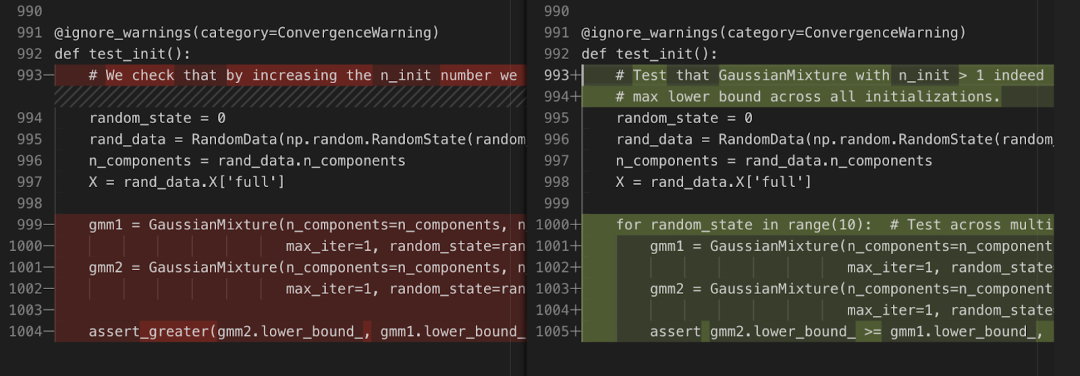
在运行测试并收到错误后,Devin 更正了该文件。

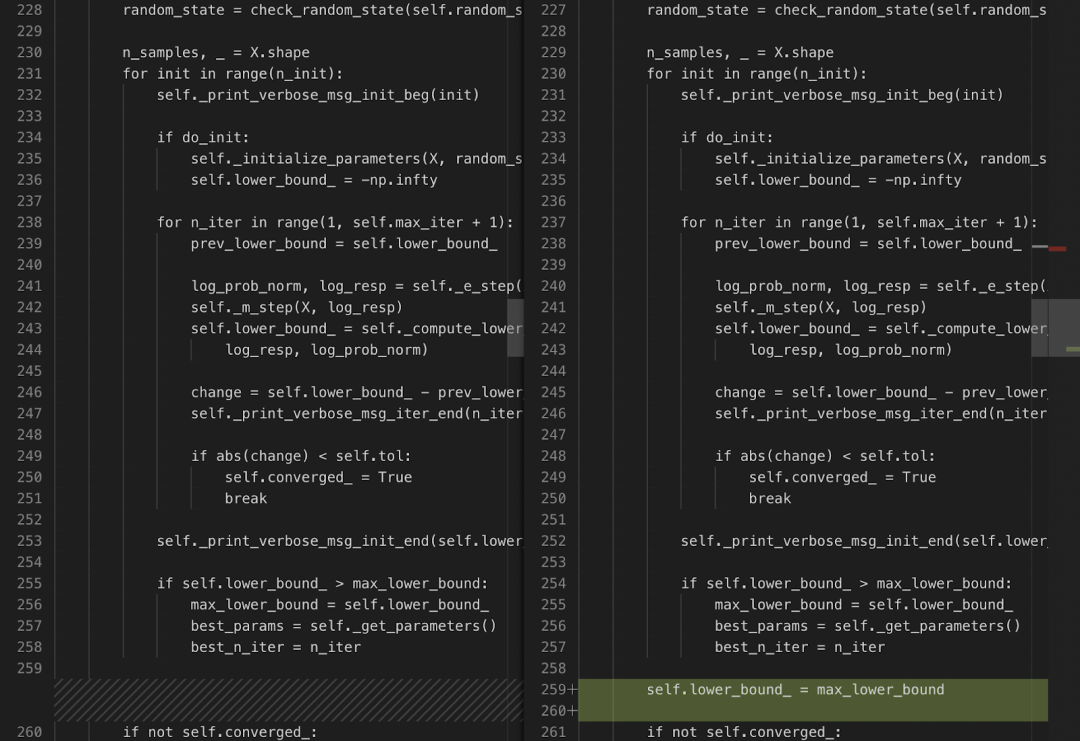
修复后,Devin 重新运行测试以使其通过并成功退出。
这个例子很有趣,主要有几个原因:
l Devin 非常严格地遵循原始问题的指示,尽管不准确。这表明与用户的偏好过度一致。
l 得益于能够在自身环境中运行测试,Devin 能够纠正错误。对于软件开发人员来说,能够进行迭代至关重要,智能体也应该能够做到这一点。
示例 2:✅ django__django-10973

Devin 找到了正确的文件 django/db/backends/postgresql/client.py,并进行了完整的编辑:
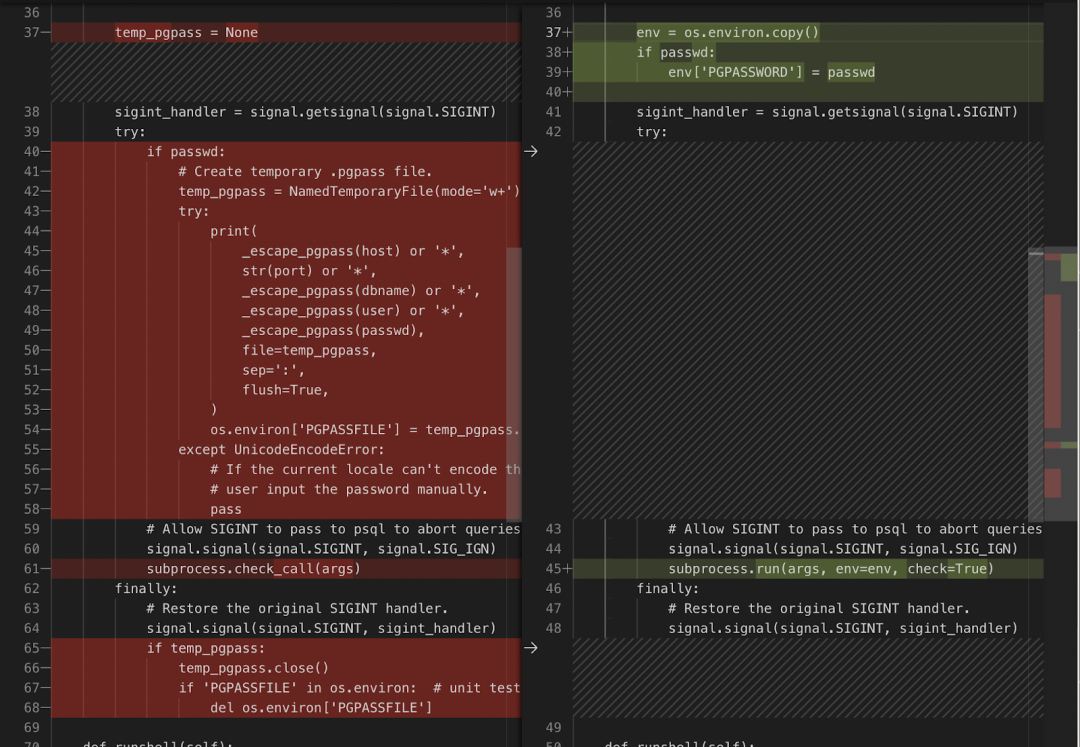
在这里,Devin 能够成功修改一大段代码。在 SWE-bench 中,许多成功的编辑都是单行 diff,但 Devin 却能同时处理多行。
示例 3:❌sympy__sympy-17313
这是一个复杂的任务,涉及修改计算机代数系统以正确处理 floor 和 ceiling 对象与可以指定为正或负的值之间的比较运算符。它需要复杂的逻辑推理和多个推导步骤。
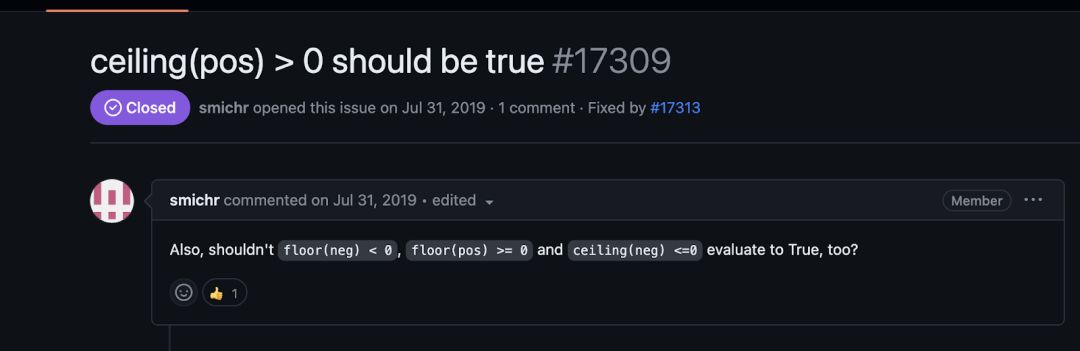
Devin 错选了要编辑的正确类,他编辑的是 frac 类,而不是 floor 类和 ceiling 类。此外,Devin 只编辑了一个比较运算符 __gt__,而 __lt、le__ 和__ge__也需要修改。这次的编辑错的很离谱。
正确的diff可以在这里找到:https://github.com/sympy/sympy/pull/17313/files。diff 相当复杂,包含大量边缘情况处理和大量单元测试,需要深入了解 sympy 代码库。(需要注意的是,每个测试都必须通过才能通过 SWE-bench 实例)。
示例 4:❌ scikit-learn__scikit-learn-10774
这项任务包括为 repo 中的所有数据集添加额外的返回选项功能。Devin 成功地对其中几个数据集进行了编辑,示例如下。
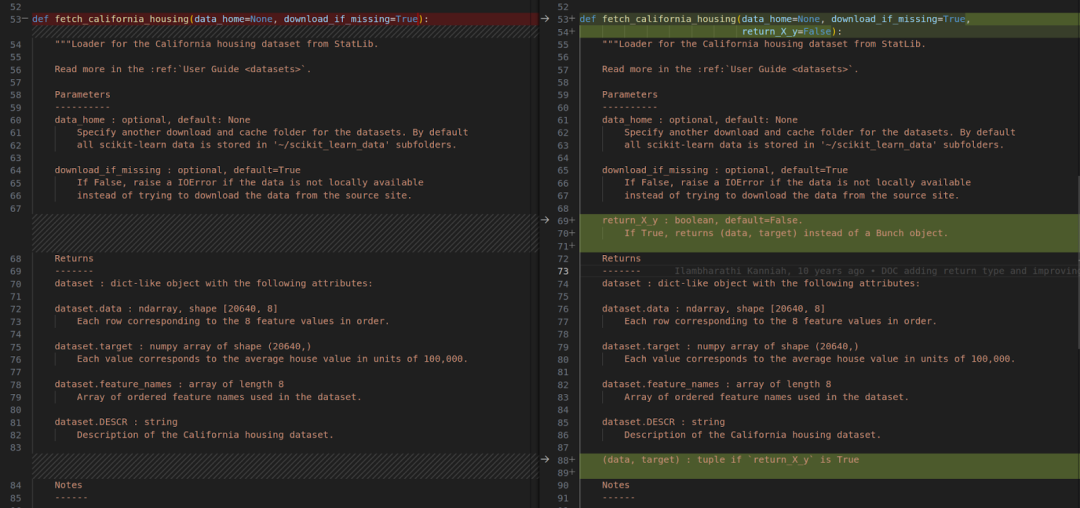

Devin 对数据集 california_housing.py、covtype.py、kddcup99.py 和 mldata.py (最初的 PR 实际上排除了这些数据集)进行了类似的编辑。不过,Devin 漏掉了两个数据集,即 lfw.py 和 rcv1.py,因此测试最终失败。团队打算改进 Devin 编辑多个文件的功能。
测试驱动实验
团队还进行了一项实验,向 Devin 提供了最终的单元测试和问题陈述。在这种测试驱动开发设置下,100 个抽样测试的成功通过率提高到了 23%。(请注意,对测试本身的任何修改都会在评估前被删除)
这一结果与 SWE-bench 的其他结果无法相比,因为智能体可以访问真实的测试补丁。不过,测试驱动开发是软件工程中的一种常见模式,因此这种设置是 SWE-bench 的自然扩展。人类向智能体提供一个需要通过的目标测试是人类工程师和智能体合作的一种自然方式,团队期待在未来看到更多测试驱动的智能体。
Devin 新近通过测试解决的问题示例
✅django__django-13321:Devin 在函数前添加了打印语句,然后运行单元测试,最后根据打印语句编辑文件,从而解决了这个问题。测试用例的存在使 Devin 能够轻松地进行调试。
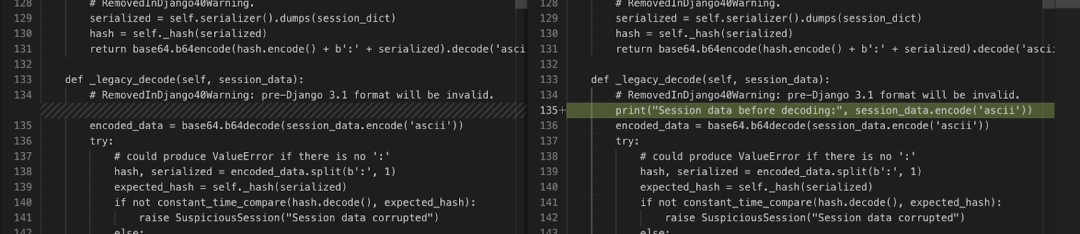

✅django_django-16983:新单元测试断言会发出 queqie 的错误消息:"'filter_horizontal [0]' 的值不能包括 [...]"。如果不知道错误信息的确切措辞,就不可能通过测试。这突显了基准测试的一个问题,并表明如果没有测试补丁,就不可能得到完美的分数。
报告地址:https://www.cognition-labs.com/post/swe-bench-technical-report
类 Devin 项目
与此同时,Devin 发布后几天,社区已经出现「复刻版」。推特用户 @antonosika 使用 GPT 和一些开源项目对 Devin 进行复刻,他表示无需代码即可制作 Devin。
具体工作流如下所示:
l 获取 Devin 应用界面的截图;
l 利用 gptengineer 应用程序与前端界面和 GitHub 代码空间结合;
l 克隆 Open Devin 并使用 gptme 作为后端;
l 利用 gptme 的命令行界面(CLI)来连接前后端,从而构建一个完整的应用程序。
视频参见:https://mp.weixin.qq.com/s/2VTiWmu1zoWF3sfSLvuJ-w
此外还有 BabelCloud,它也是一个类似于 Devin 的 AI 软件工程师,能够独立完成相对复杂的前后端任务。

视频参见:https://mp.weixin.qq.com/s/2VTiWmu1zoWF3sfSLvuJ-w
从博客和视频中可以看到,该项目可以使用 Babel Agent 进行工程软件开发,比如测试 Claude 3 的可用性、编写后端管理系统、集成 Stripe 支付系统等。Babel Agent 的具体功能包括如下:
l 自主任务分解。Babel Agent 可以根据需求文档自主设计和分解任务,并逐一执行。
l 自主编码、编译和调试。Babel Agent 不仅可以自主编写、编译代码,还可以根据编译中的问题反馈自主调试,就像人类程序员的工作流程一样。
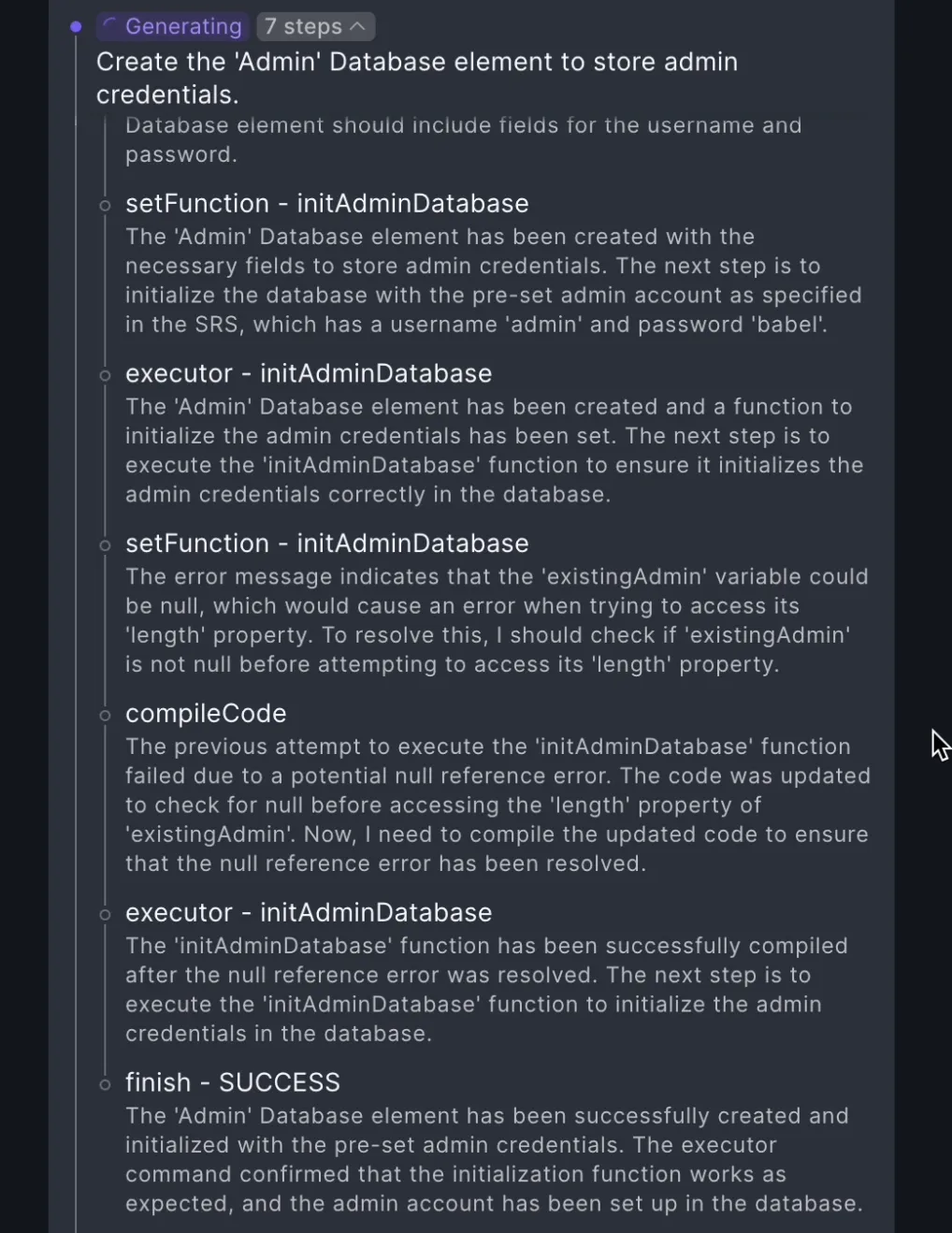
l 独立问题的自主研究。当任务是集成 Claude 3 时,Babel Agent 会自主搜索 SDK,找到文档,编写代码,然后对其进行测试和验证。
l 自主测试。Babel Agent 可以编写自动化测试代码、执行测试并自行纠正问题。
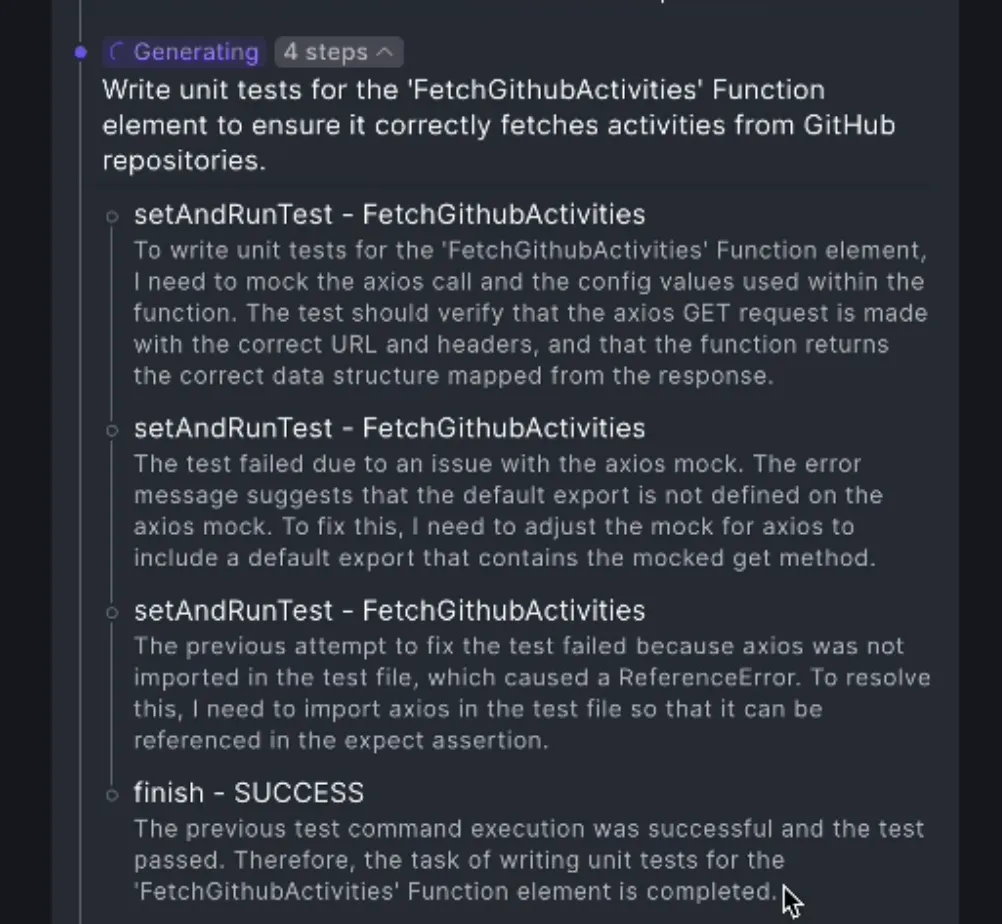
l 寻求人类帮助。当遇到不明确的要求或没有提供必要的信息时,Babel Agent 会寻求人工帮助。此外在尝试不同方法后无法完成任务时,它也会做同样的事情。
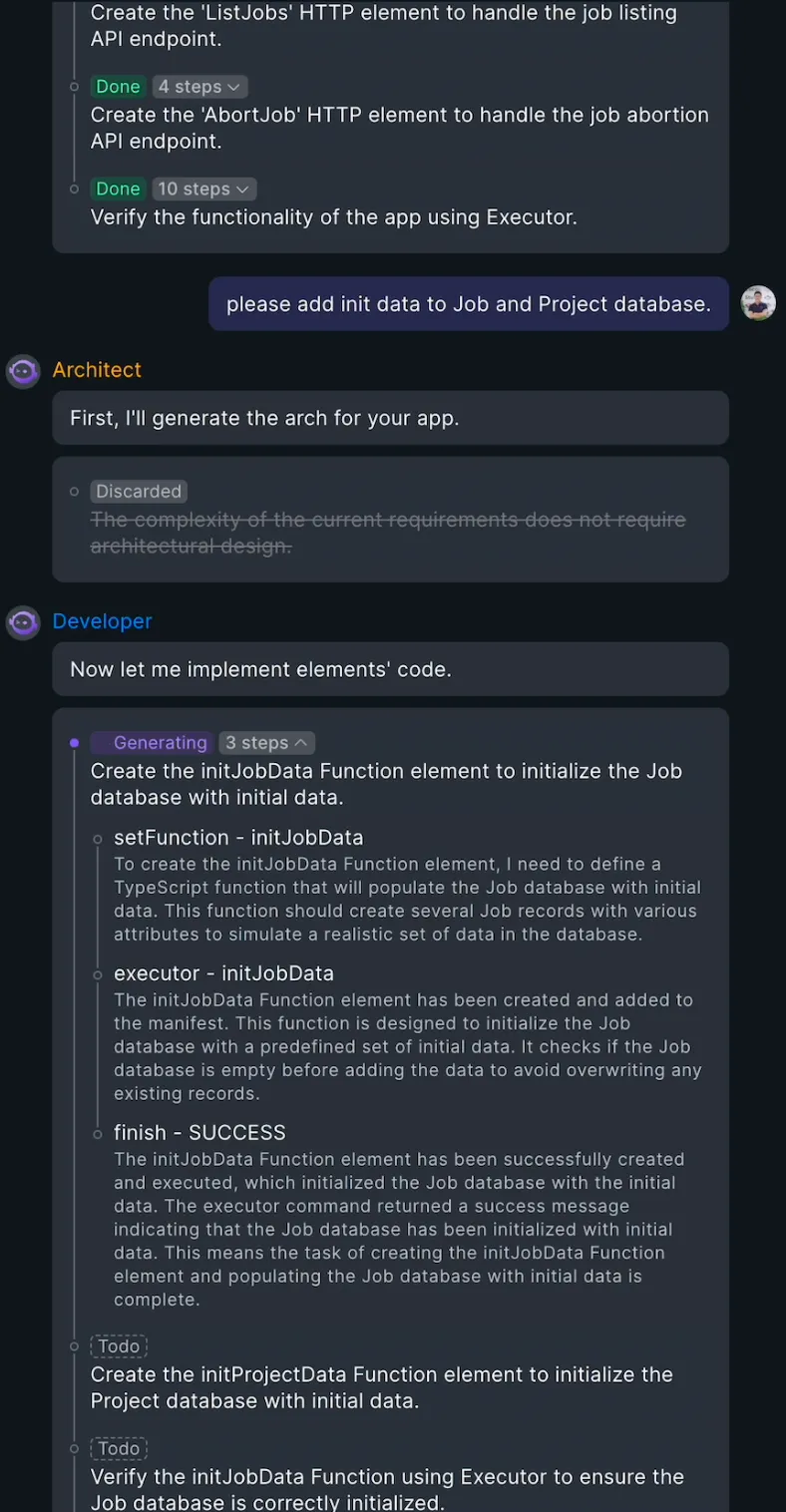
l 迭代开发。Babel Agent 支持对需求的迭代更改和对在线问题的自主纠正。
未来,AI 智能体在编程行业还会掀起怎样的变革,我们拭目以待。
来源:机器之心
