谷歌推出全球最大通用大模型之一RT-X,并开放训练数据集
发布时间:2023-10-1110月4日,谷歌旗下著名AI研究机构DeepMind在官网发布了,全球最大通用大模型之一RT-X,并开放了训练数据集Open X-Embodiment。
据悉,RT-X由控制模型RT-1-X和视觉模型RT-2-X组成,在特定任务(搬运东西、开窗等)的工作效率是同类型机器人的3倍,同时可执行未训练动作。
Open X-Embodiment训练数据集由全球33家顶级学术实验室合作,整合了来自22种不同机器人类型的数据开发而成。
简单来说,谷歌将全球最全的机器人训练数据集整合在一起,训练了一个通用机器人模型。值得一提的是,上海交通大学也参与了该项目,在技术研究方面做出了重要贡献。
模型和数据集地址:https://robotics-transformer-x.github.io/
论文地址:https://robotics-transformer-x.github.io/paper.pdf
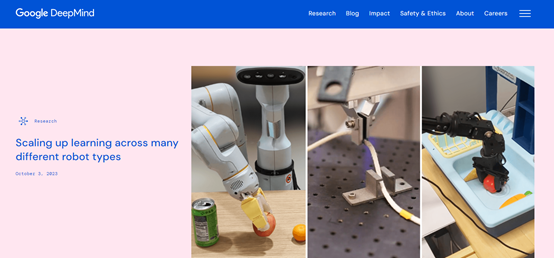
谷歌表示,AI机器人非常强大,但在通用方面却很差。例如,我们想开发一款物理扫地机器人,需要根据特定的环境、动作、障碍、反馈等数据进行漫长地训练,然后进行反复测试才能完成产品研发。

为了打破这一困局,谷歌联合33家顶级学术机构,整合了目前最全面的22种不同类型的数据,打造了通用数据集Open X-Embodiment,然后在此基础之上训练了通用大模型——RT-X。
这意味着,RT-X可以在无需任何训练数据或极少训练的情况下,就能完成一些特定任务或工作,例如,仓库搬运、防爆救险、家庭护理等,这对于机器人的商业化落地发挥巨大作用。
RT-X模型简单介绍
开发人员使用RT-1(用于大规模实际机器人控制的模型)训练了RT-1-X,并使用RT-2(视觉-语言-动作模型,可从网络和机器人数据中学习)训练了RT-2-X。
通过这种方式,研发人员证明了,在给定相同模型架构的情况下,RT-1-X和RT-2-X得益于更多样化、跨实体的训练数据,能够实现更高的性能,在特定领域训练的模型上的改进,表现出更好的泛化能力和新的功能。

为了在合作学术大学中评估 RT-1-X,将其与特定任务(例如开门)开发的模型在相应数据集上的表现进行了比较。使用Open X-Embodiment 数据集训练的 RT-1-X 平均性能优于原始模型 50%。

为了测试RT-2的通用功能,开发人员使用RT-2执行了一些训练数据中不存在的动作、功能。结果显示,RT-2可以执行从未训练的操作,包括对空间的更好理解,对动作的细腻程度等。

例如,让RT-2把苹果拿到布附近,而不是拿到布上面。RT-2都能很好的区别这些指令的差异,并做出相应的动作。
Open X-Embodiment训练数据集介绍
训练数据集,在开发通用大模型方面发挥了重要作用。为了开发Open X-Embodiment数据集,谷歌与超过20个机构的学术研究实验室合作,从22种机器人实体中收集数据,在超过100 万个场景中展示了 500 多种技能和 150,000 项任务——这也是同类中最全面的机器人数据集。

构建一个包含各种机器人示范的数据集,是训练通用型模型的关键步骤,这种模型可以控制许多不同类型的机器人,遵循多样化的指令,对复杂任务进行基本推理,并有效地泛化。
然而,收集这样一个数据集对任何单个实验室来说都太耗费资源。因此,谷歌希望开放Open X-Embodiment数据集,可以推动整个机器人技术发展的进程。
来源:腾讯网
