650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
发布时间:2023-06-21在大模型方向上,科技巨头在训更大的模型,学界则在想办法搞优化。最近,优化算力的方法又上升到了新的高度。
大型语言模型(LLM)彻底改变了自然语言处理(NLP)领域,展示了涌现、顿悟等非凡能力。然而,若想构建出具备一定通用能力的模型,就需要数十亿参数,这大幅提高了 NLP 研究的门槛。在 LLM 模型调优过程中通常又需要昂贵的 GPU 资源,例如 8×80GB 的 GPU 设备,这使得小型实验室和公司很难参与这一领域的研究。
最近,人们正在研究参数高效的微调技术(PEFT),例如 LoRA 和 Prefix-tuning,为利用有限资源对 LLM 进行调优提供了解决方案。然而,这些方法并没有为全参数微调提供实用的解决方案,而全参数微调已被公认为是比参数高效微调更强大的方法。
在上周复旦大学邱锡鹏团队提交的论文《Full Parameter Fine-tuning for Large Language Models with Limited Resources》中,研究人员提出了一种新的优化器 LOw-Memory Optimization(LOMO)。
通过将 LOMO 与现有的内存节省技术集成,与标准方法(DeepSpeed 解决方案)相比,新方法将内存使用量减少到了之前的 10.8%。因此,新方法能够在一台具有 8×RTX 3090 的机器上对 65B 模型进行全参数微调,每个 RTX 3090 具有 24GB 内存。

论文链接:https://arxiv.org/abs/2306.09782
在该工作中,作者分析了 LLM 中内存使用的四个方面:激活、优化器状态、梯度张量和参数,并对训练过程进行了三方面的优化:
1. 从算法的角度重新思考了优化器的功能,发现 SGD 在微调 LLM 完整参数方面是一种很好的替代品。这使得作者可以删除优化器状态的整个部分,因为 SGD 不存储任何中间状态。
2. 新提出的优化器 LOMO 将梯度张量的内存使用量减少到 O (1),相当于最大梯度张量的内存使用量。
3. 为了使用 LOMO 稳定混合精度训练,作者集成了梯度归一化、损失缩放,并在训练期间将某些计算转换为全精度。
新技术让内存的使用等于参数使用加上激活和最大梯度张量。全参数微调的内存使用被推向了极致,其仅等同于推理的使用。这是因为 forward+backward 过程的内存占用应该不会比单独的 forward 过程少。值得注意的是,在使用 LOMO 节省内存时,新方法确保了微调过程不受影响,因为参数更新过程仍然等同于 SGD。
该研究评估了 LOMO 的内存和吞吐量性能,表明借助 LOMO,研究者在 8 个 RTX 3090 GPU 上就可以训练 65B 参数的模型。此外,为了验证 LOMO 在下游任务上的性能,他们应用 LOMO 来调优 SuperGLUE 数据集集合上 LLM 的全部参数。结果表明了 LOMO 对具有数十亿参数的 LLM 进行优化的有效性。
方法介绍
在方法部分,本文详细介绍了 LOMO(LOW-MEMORY OPTIMIZATION)。一般而言,梯度张量表示一个参数张量的梯度,其大小与参数相同,这样一来内存开销较大。而现有的深度学习框架如 PyTorch 会为所有参数存储梯度张量。现阶段,存储梯度张量有两方面原因:计算优化器状态以及归一化梯度。
由于该研究采用 SGD 作为优化器,因此没有依赖于梯度的优化器状态,并且他们有一些梯度归一化的替代方案。
他们提出了 LOMO,如算法 1 所示,LOMO 将梯度计算与参数更新融合在一个步骤中,从而避免了梯度张量的存储。
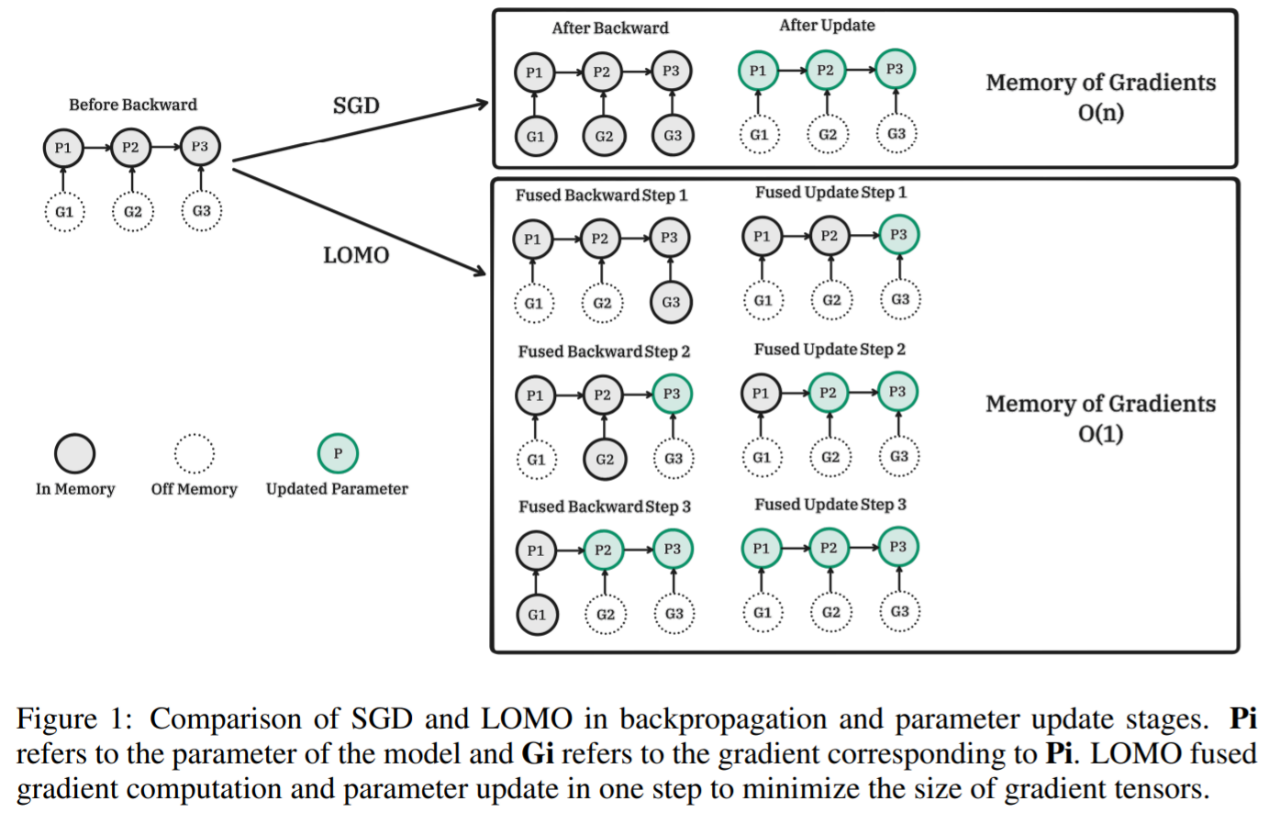
下图为 SGD 和 LOMO 在反向传播和参数更新阶段的比较。Pi 为模型参数,Gi 为 Pi 对应的梯度。LOMO 将梯度计算和参数更新融合到一个步骤中,使梯度张量最小。
LOMO 对应的算法伪代码:

具体而言,该研究将 vanilla 梯度下降表示为![]() ,这是一个两步过程,首先是计算梯度,然后更新参数。融合版本为
,这是一个两步过程,首先是计算梯度,然后更新参数。融合版本为 ![]() 。
。
该研究的关键思想是在计算梯度时立即更新参数,这样就不会在内存中存储梯度张量。这一步可以通过在向反向传播中注入 hook 函数来实现。PyTorch 提供了注入 hook 函数的相关 API,但却无法用当前的 API 实现精确的即时更新。相反,该研究在内存中最多存储一个参数的梯度,并随着反向传播逐一更新每个参数。本文方法减少了梯度的内存使用,从存储所有参数的梯度到只存储一个参数的梯度。
大部分 LOMO 内存使用与参数高效微调方法的内存使用一致,这表明 LOMO 与这些方法相结合只会导致梯度占用内存的轻微增加。这样就可以为 PEFT 方法调优更多的参数。
实验结果
在实验部分,研究者从三个方面评估了他们提出的方法,即内存使用情况、吞吐量和下游性能。如果不作进一步解释,所有的实验都是用 7B 到 65B 的 LLaMA 模型进行的。
内存使用情况
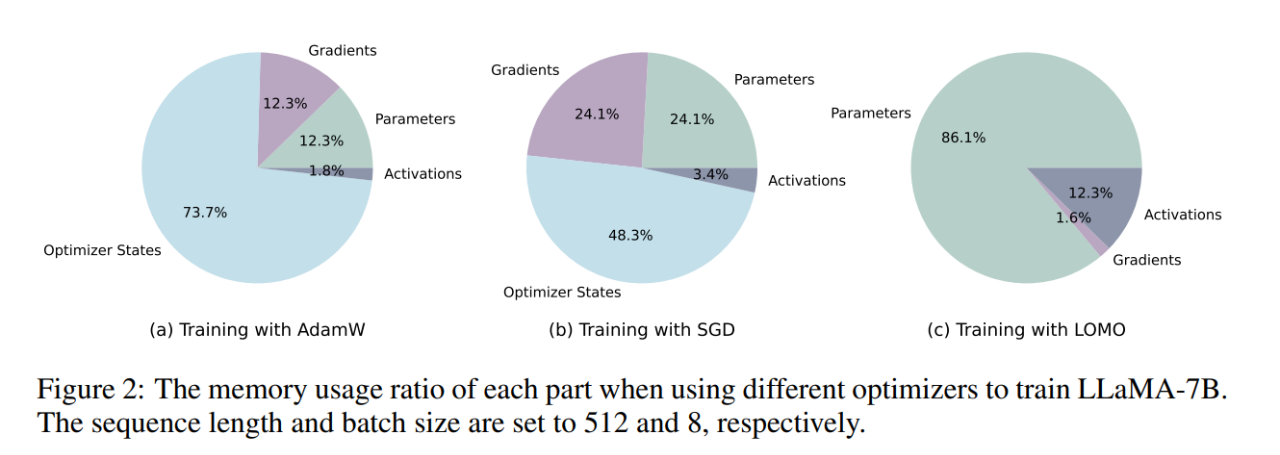
研究者首先剖析了,在不同设置下,训练期间的模型状态和激活的内存使用情况。如表 1 所示,与 AdamW 优化器相比,LOMO 优化器的使用导致内存占用大幅减少,从 102.20GB 减少到 14.58GB;与 SGD 相比,在训练 LLaMA-7B 模型时,内存占用从 51.99GB 减少到 14.58GB。内存用量的大幅减少主要归因于梯度和优化器状态的内存需求减少。因此,在训练过程中,内存大部分被参数占据,与推理过程中的内存用量相当。

如图 2 所示,如果采用 AdamW 优化器进行 LLaMA-7B 训练,相当大比例的内存(73.7%)被分配给优化器状态。用 SGD 优化器替换 AdamW 优化器可以有效减少优化器状态占用内存的百分比,从而减轻 GPU 内存使用(从 102.20GB 减少到 51.99GB)。如果使用 LOMO,参数更新和 backward 会被融合到一个步骤中,进一步消除优化器状态对内存的需求。
吞吐量
研究者比较了 LOMO、AdamW 和 SGD 的吞吐性能。实验是在一台配备了 8 个 RTX 3090 GPU 的服务器上进行的。
对于 7B 的模型,LOMO 的吞吐量呈现显著优势,超过 AdamW 和 SGD 约 11 倍。这一重大改进可归功于 LOMO 在单个 GPU 上训练 7B 模型的能力,这减少了 GPU 间的通信开销。与 AdamW 相比,SGD 的吞吐量略高,这可归因于 SGD 排除了动量和方差的计算。
至于 13B 模型,由于内存的限制,它无法在现有的 8 个 RTX 3090 GPU 上用 AdamW 训练。在这种情况下,模型的并行性对 LOMO 来说是必要的,LOMO 在吞吐量方面仍然优于 SGD。这一优势归功于 LOMO 的内存高效特性,以及只需要两个 GPU 以相同的设置来训练模型,从而降低了通信成本,提高了吞吐量。此外,在训练 30B 模型时,SGD 在 8 个 RTX 3090 GPU 上遇到了内存不足(OOM)的问题,而 LOMO 在只有 4 个 GPU 的情况下表现良好。
最后,研究者使用 8 个 RTX 3090 GPU 成功训练了 65B 模型,实现了 4.93 TGS 的吞吐量。利用这样的服务器配置和 LOMO,模型在 1000 个样本上的训练过程(每个样本包含 512 个 token)大约需要 3.6 小时。
下游性能
为了评估 LOMO 在微调大型语言模型方面的有效性,研究者进行了一系列广泛的实验。他们将 LOMO 与其他两种方法进行比较,一种是不需要微调的 Zero-shot,另一种是目前很流行的参数高效微调技术 LoRA。
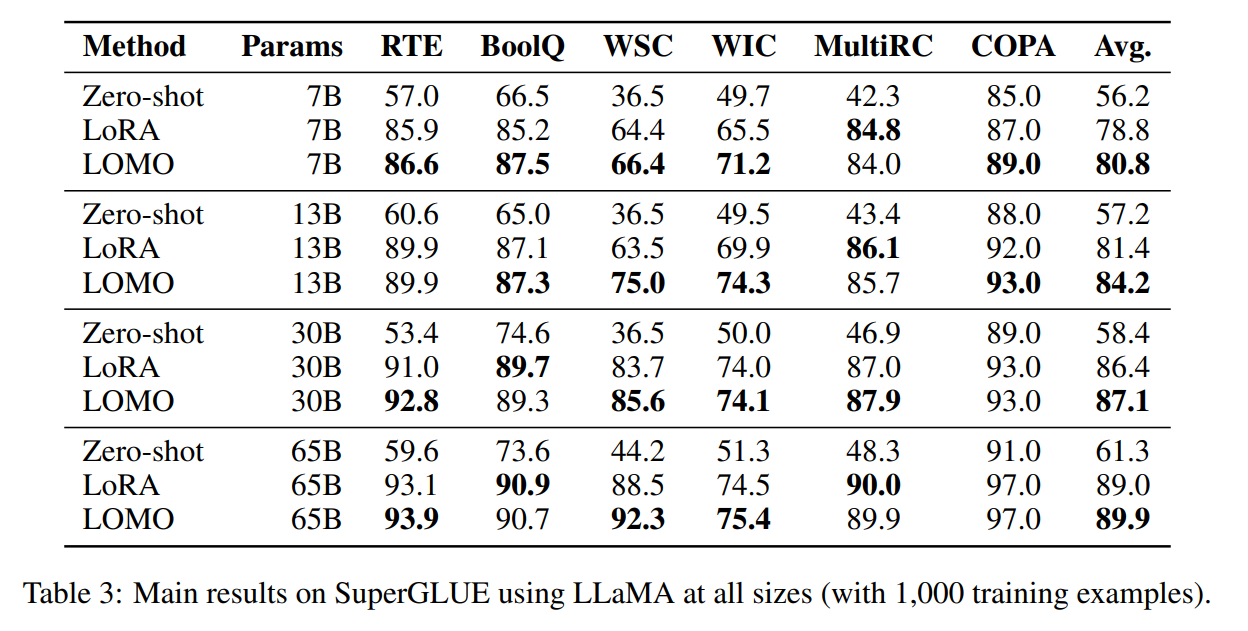
表 3 结果显示:
l LOMO 的表现明显好于 Zero-shot;
l 在大多数实验中,LOMO 普遍优于 LoRA;
l LOMO 可以有效扩展至 650 亿参数的模型。
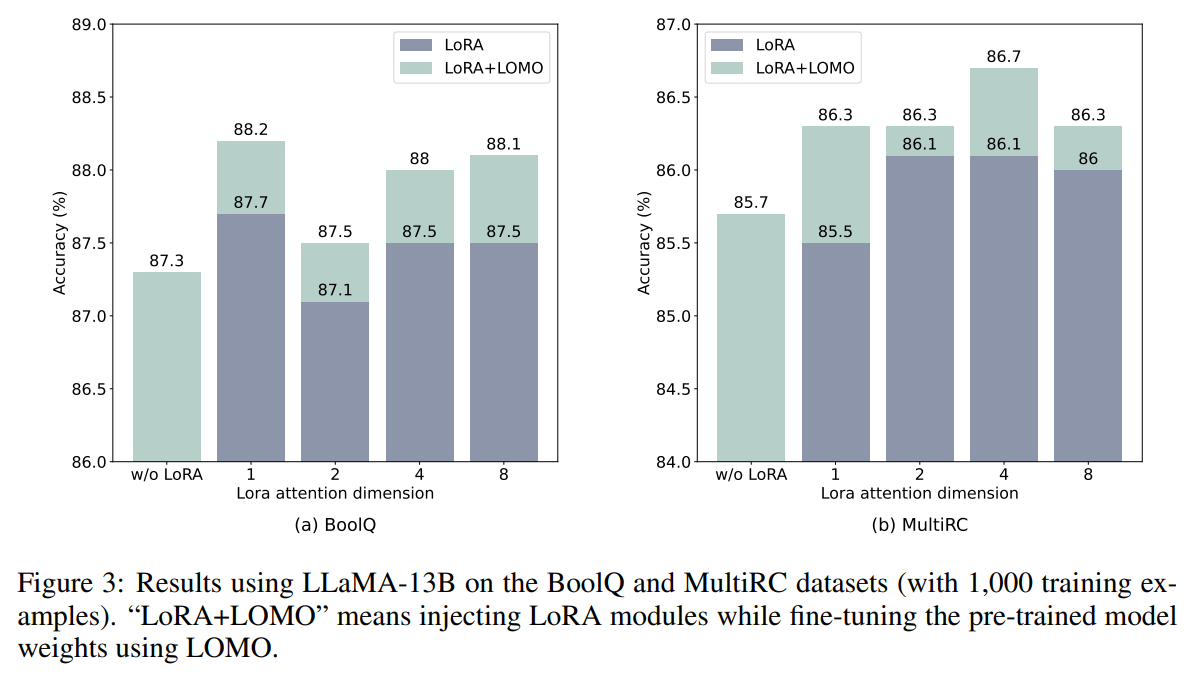
LOMO 和 LoRA 在本质上是相互独立的。为了验证这一说法,研究者使用 LLaMA-13B 在 BoolQ 和 MultiRC 数据集上进行了实验。结果如图 3 所示。
他们发现,LOMO 在持续增强 LoRA 的性能,不管 LoRA 取得的结果有多高。这表明,LOMO 和 LoRA 采用的不同微调方法是互补的。具体来说,LOMO 专注于微调预训练模型的权重,而 LoRA 则调整其他模块。因此,LOMO 不会影响到 LoRA 的性能;相反,它有助于对下游任务进行更好的模型调优。
更多细节参见原论文。
来源:机器之心
