一句话生成3D模型:AI扩散模型的突破,让建模师慌了
发布时间:2022-11-30我们生活在三维的世界里,尽管目前大多数应用程序是 2D 的,但人们一直对 3D 数字内容有很高的需求,包括游戏、娱乐、建筑和机器人模拟等应用。
然而,创建专业的 3D 内容需要很高的艺术与审美素养和大量 3D 建模专业知识。人工完成这项工作需要花费大量时间和精力来培养这些技能。
需求大又是「劳动密集型行业」,那么有没有可能交给 AI 来做?上周五,英伟达提交到预印版论文平台 arXiv 的论文引起了人们的关注。
和现在流行的 NovelAI 差不多,人们只需要输入一段文字比如「一只坐在睡莲上的蓝色箭毒蛙」,AI 就能给你生成个纹理造型俱全的 3D 模型出来。

Magic3D 还可以执行基于提示的 3D 网格编辑:给定低分辨率 3D 模型和基本提示,可以更改文本从而修改生成的模型内容。此外,作者还展示了保持画风,以及将 2D 图像样式应用于 3D 模型的能力。

Stable Diffusion 的论文在 2022 年 8 月才首次提交,几个月就已经进化到这样的程度,不禁让人感叹科技发展的速度。
英伟达表示,你只需要在这个基础上稍作修改,生成的模型就可以当做游戏或 CGI 艺术场景的素材了。
3D 生成模型的方向并不神秘,其实在 9 月 29 日,谷歌曾经发布过一款文本到 3D 的生成模型 DreamFusion,英伟达在 Magic3D 的研究中直接对标该方法。

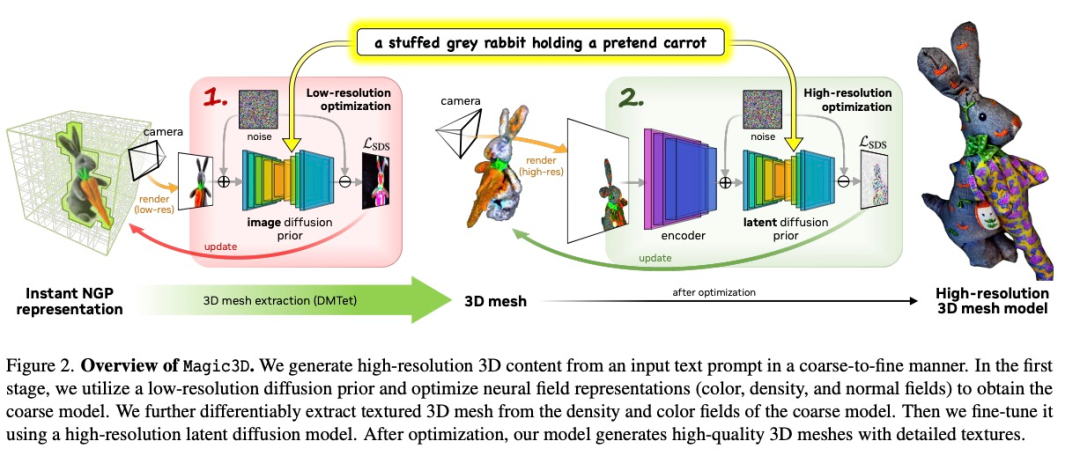
类似于 DreamFusion 用文本生成 2D 图像,再将其优化为体积 NeRF(神经辐射场)数据的流程,Magic3D 使用两阶段生成法,用低分辨率生成的粗略模型再优化到更高的分辨率。
英伟达的方法首先使用低分辨率扩散先验获得粗糙模型,并使用稀疏 3D 哈希网格结构进行加速。用粗略表示作为初始,再进一步优化了带纹理的 3D 网格模型,该模型具有与高分辨率潜在扩散模型交互的高效可微分渲染器。
Magic3D 可以在 40 分钟内创建高质量的 3D 网格模型,比 DreamFusion 快 2 倍(后者平均需要 1.5 小时),同时还实现了更高的分辨率。统计表明相比 DreamFusion,61.7% 的人更喜欢英伟达的新方法。
连同图像调节生成功能,新技术为各种创意应用开辟了新途径。

论文链接:https://arxiv.org/abs/2211.10440
技术细节
Magic3D 可以在较短的计算时间内根据文本 prompt 合成高度详细的 3D 模型。Magic3D 通过改进 DreamFusion 中的几个主要设计选择来使用文本 prompt 合成高质量的 3D 内容。
具体来说,Magic3D 是一种从粗到精的优化方法,其中使用不同分辨率下的多个扩散先验来优化 3D 表征,从而生成视图一致的几何形状以及高分辨率细节。Magic3D 使用监督方法合成 8 倍高分辨率的 3D 内容,速度也比 DreamFusion 快 2 倍。
Magic3D 的整个工作流程分为两个阶段:在第一阶段,该研究优化了类似于 DreamFusion 的粗略神经场表征,以实现具有基于哈希网格(hash grid)的内存和计算的高效场景表征。
在第二阶段该方法切换到优化网格表征。这个步骤很关键,它允许该方法在高达 512 × 512 的分辨率下利用扩散先验。由于 3D 网格适用于快速图形渲染,可以实时渲染高分辨率图像,因此该研究利用基于光栅化的高效微分渲染器和相机特写来恢复几何纹理中的高频细节。
基于上述两个阶段,该方法可以生成高保真的 3D 内容,并且很容易在标准图形软件中导入和可视化。
此外,该研究展示了用文本 prompt 对 3D 合成过程的创造性控制能力,如下图 1 所示。

为了对比实际应用效果,英伟达的研究人员把 Magic3D 和 DreamFusion 在 397 个文本提示生成的内容上进行了比较。平均的粗略模型生成阶段花费 15 分钟,精细阶段训练了 25 分钟,所有运行时间均在 8 块英伟达 A100 GPU 上测得。


虽然论文和 demo 只是第一步,但英伟达已经为 Magic3D 想好了未来的应用方向:给游戏和元宇宙世界提供制作海量 3D 模型的工具,而且让所有人都可以上手使用。
当然,最早上线这项功能的可能会是英伟达自己的 Omniverse。
来源:机器之心
