对人胜率84%,DeepMind AI首次在西洋陆军棋中达到人类专家水平
发布时间:2022-07-28在AI游戏领域,人工智能的进展往往通过棋盘游戏进行展现。棋盘游戏可以度量和评估人类和机器如何在受控环境中发展和执行策略。数十年来,提前规划的能力一直是AI在国际象棋、跳棋、将棋和围棋等完美信息游戏以及扑克、苏格兰场等不完美信息游戏中取得成功的关键。
西洋陆军棋(Stratego)已经成为AI研究的下一批前沿领域之一。该游戏的阶段和机制的可视化图如下1a所示。该游戏面临以下两个挑战。
其一,Stratego 的博弈树具有 10^535个可能状态,这要多于已经得到充分研究的不完美信息游戏无限制德州扑克(10^164个可能状态)和围棋游戏(10^360个可能状态)。
其二,在Stratego的给定环境中行动需要在游戏开始时为每个玩家推理超过10^66个可能的部署,而扑克只有10^3对可能的牌。围棋和国际象棋等完美信息游戏没有私有部署阶段,因此避免了Stratego中这一挑战带来的复杂性。
目前,我们不可能使用基于模型的SOTA完美信息规划技术,也无法使用将游戏分解为独立情况的不完美信息搜索技术。
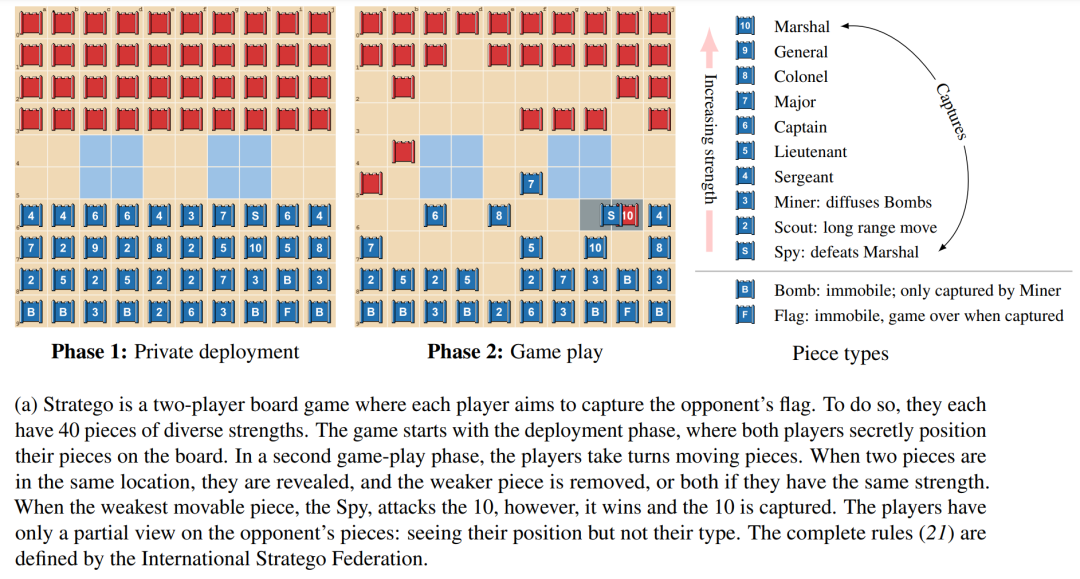
由于这些原因,Stratego为研究大规模策略交互提供了一个挑战性基准。与大多数棋盘游戏相似,Stratego测试我们循序地做出相对较慢、深思熟虑和合乎逻辑决策的能力。又由于该游戏的结构非常复杂,AI研究社区几乎没能取得什么进展,人工智能体只能达到人类业余玩家的水平。因此,在从零开始且没有人类演示数据的情况下,开发智能体学习端到端策略以在Stratego的不完美信息下做出最佳决策,仍然是AI研究面临的重大挑战之一。
近日,在 DeepMind 的一篇最新论文中,研究者提出了 DeepNash,它是一种无需人类演示、以无模型(model-free)方式学习Stratego自我博弈的智能体。DeepNask击败了以往的SOTA AI智能体,并在该游戏最复杂的变体Stratego Classic中实现了专家级人类玩家的水平。

论文地址:https://arxiv.org/pdf/2206.15378.pdf
DeepNash的核心是一种条理化、无模型的强化学习算法,研究者称为Regularized Nash Dynamics(R-NaD)。DeepNash将R-NaD与一个深度神经网络架构相结合,并收敛到纳什均衡,这意味着它学会了在激励竞争下比赛,并对试图利用它的竞争对手具有稳健性。
下图 1 b 为DeepNash方法的高级概览。研究者在Gravon游戏平台上将它的表现与各种SOTA Stratego机器人和人类玩家进行了系统比较。结果显示,DeepNash以超过 97% 的胜率击败了当前所有 SOTA机器人,并与人类玩家进行了激烈竞争,在2022年度和各个时期的排行榜上都位列前3名,胜率达到了84%。
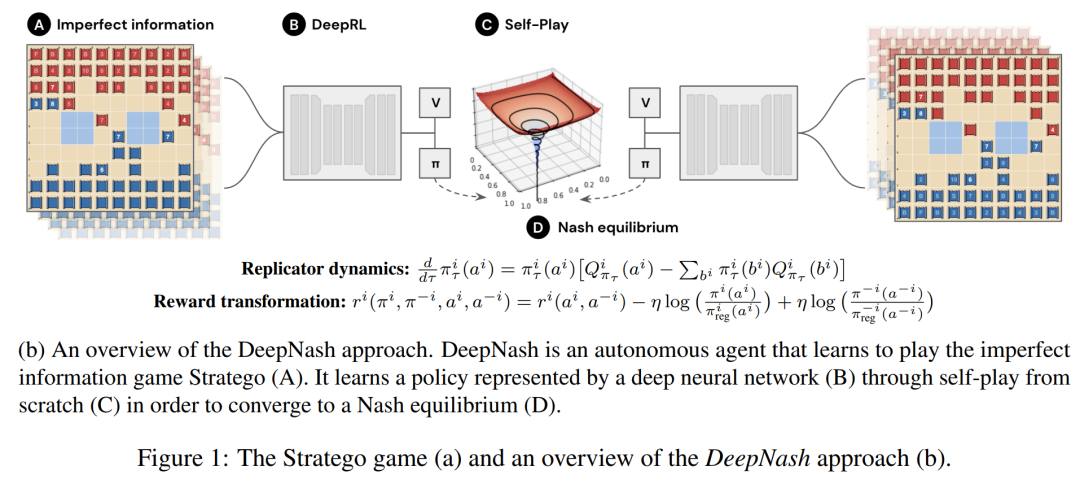
研究者表示,在学习算法中不部署任何搜索方法的情况下,AI算法第一次能够在复杂棋盘游戏中达到人类专家水平,也是AI首次在Stratego游戏中实现人类专家水平。
方法概述
DeepNash 采用端到端的学习策略运行Stratego,并在游戏开始时将棋子战术性地放在棋盘上(见图 1a),在game-play阶段,研究者使用集成深度 RL 和博弈论方法。智能体旨在通过自我博弈来学习一个近似的纳什均衡。
该研究采用无需搜索的正交路径,并提出了一种新方法,将自我博弈中的无模型(model-free)强化学习与博弈论算法思想——正则化纳什动力学 (RNaD) 相结合。
无模型部分意味着该研究没有建立一个明确的对手模型来跟踪对手可能出现的状态,博弈论部分基于这样的思路,即在强化学习方法的基础上,他们引导智能体学习行为朝着纳什均衡的方向发展。这种组合方法的主要优点是不需要从公共状态中显式地模拟私有状态。另外一个复杂的挑战是,将这种无模型的强化学习方法与R-NaD相结合,使西洋陆军棋中的自我博弈与人类专家玩家相竞争,这是迄今为止尚未实现的。这种组合的DeepNash方法如上图1b所示。
正则化纳什动力学算法
DeepNash 中使用的 R-NaD 学习算法是基于正则化思想以达到收敛的目的,R-NaD 依赖于三个关键步骤,如下图 2b所示:

DeepNash 由三个组件组成:(1) 核心训练组件 R-NaD;(2) 微调学习策略以减少模型采取极不可能动作的残差概率,以及 (3) 测试时进行后处理以过滤掉低概率动作并纠错。
DeepNash 的网络由以下组件构成:一个带有残差块和跳跃连接的 U-Net 主干,以及四个头。第一个 DeepNash 头将价值函数输出为标量,而其余三个头通过在部署和游戏期间输出其动作的概率分布来编码智能体策略。这个观测张量的结构如图3所示:
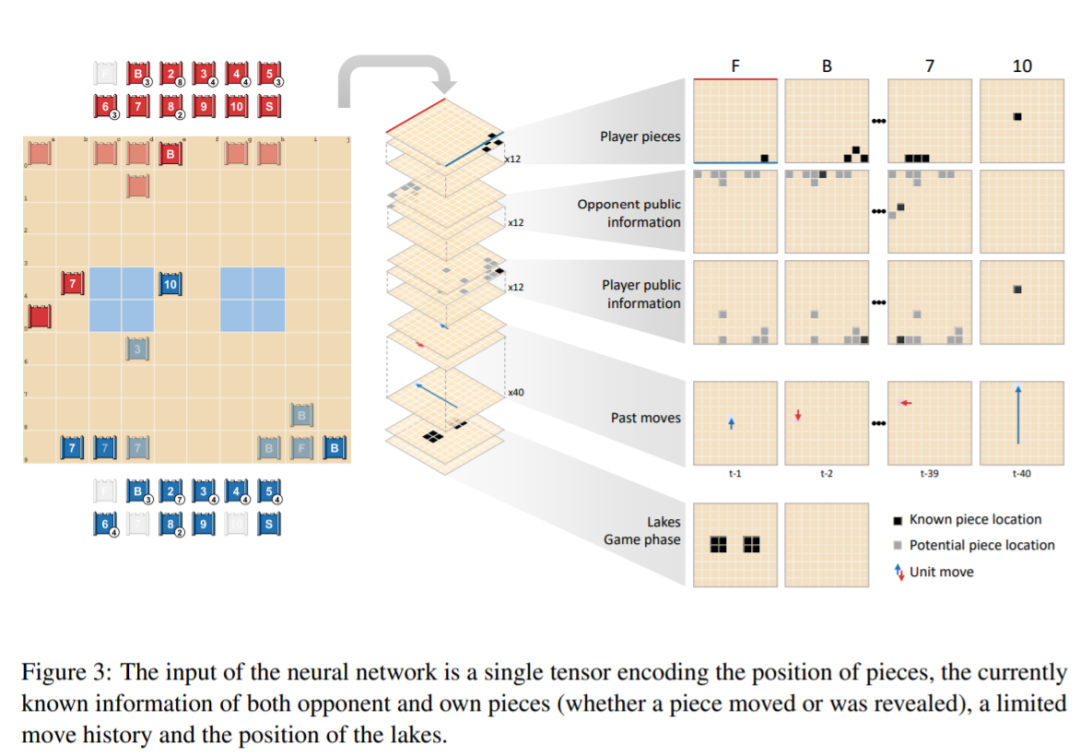
实验结果
DeepNash 还与几个现有的Stratego计算机程序进行了评估:Probe 在 Computer Stratego 世界锦标赛中,其中有三年夺冠(2007 年、2008 年、2010 年);Master of the Flag在 2009 年赢得了该冠军;Demon of Ignorance 是 Stratego 的开源实现;Asmodeus、Celsius、Celsius1.1、PeternLewis 和 Vixen 是 2012 年在澳大利亚大学编程竞赛中提交的程序,此次比赛PeternLewis 获胜。
如表1所示,DeepNash在对抗所有这些智能体时赢得了绝大多数的游戏,尽管DeepNash没有接受过对抗训练,只是使用自我博弈。

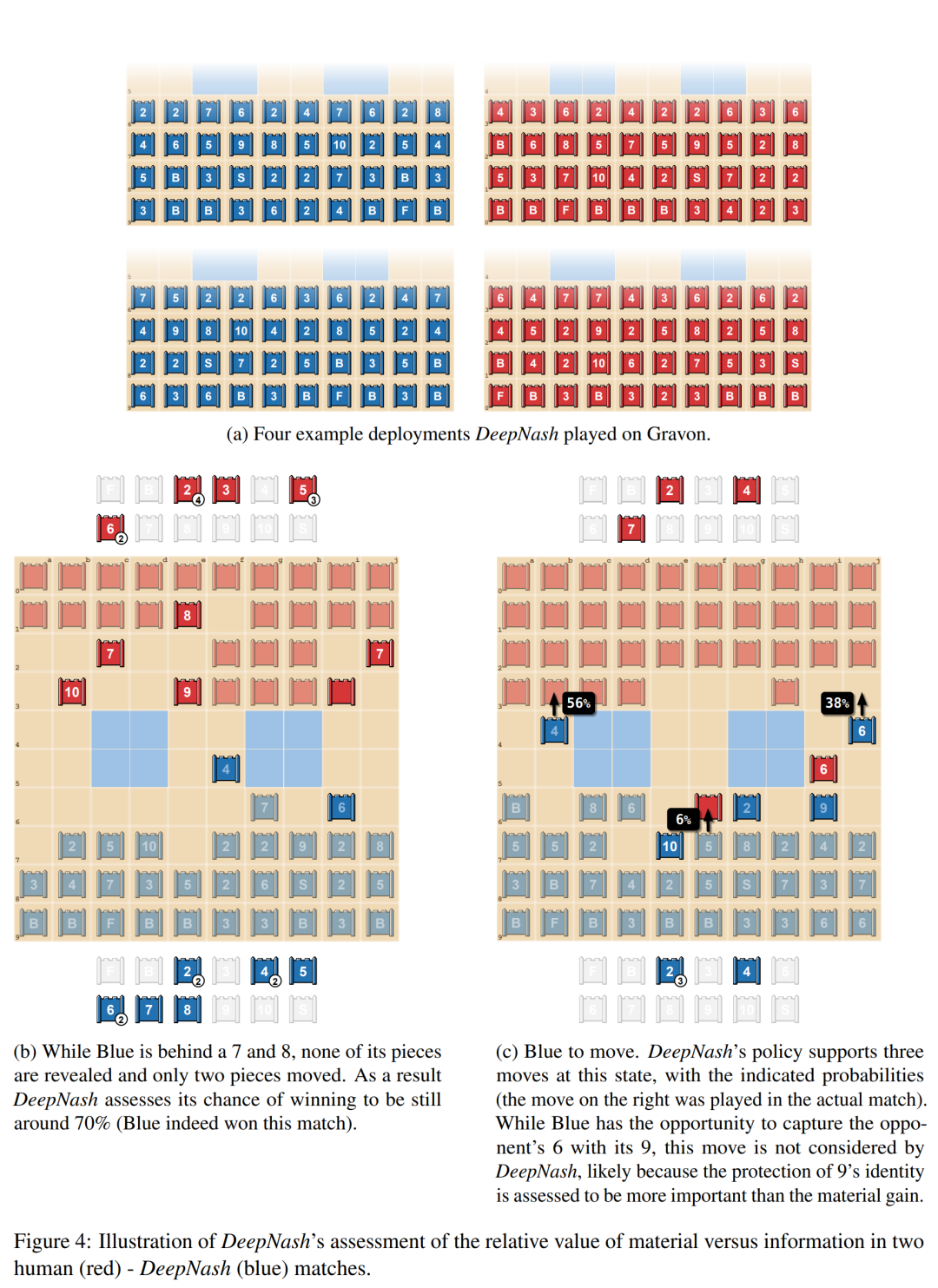
下图 4a举例说明DeepNash中的一些经常重复的部署方式;图 4b 显示了 DeepNash(蓝方)在棋子中落后(输掉了 7 和 8)但在信息方面领先的情况,因为红方的对手有 10、9、8 和两个7。图 4c 中的第二个示例显示了 DeepNash 有机会用其 9 捕获对手的 6,但这一举措并未被考虑,可能是因为DeepNash认为保护 9 的身份被认为比物质收益更重要。
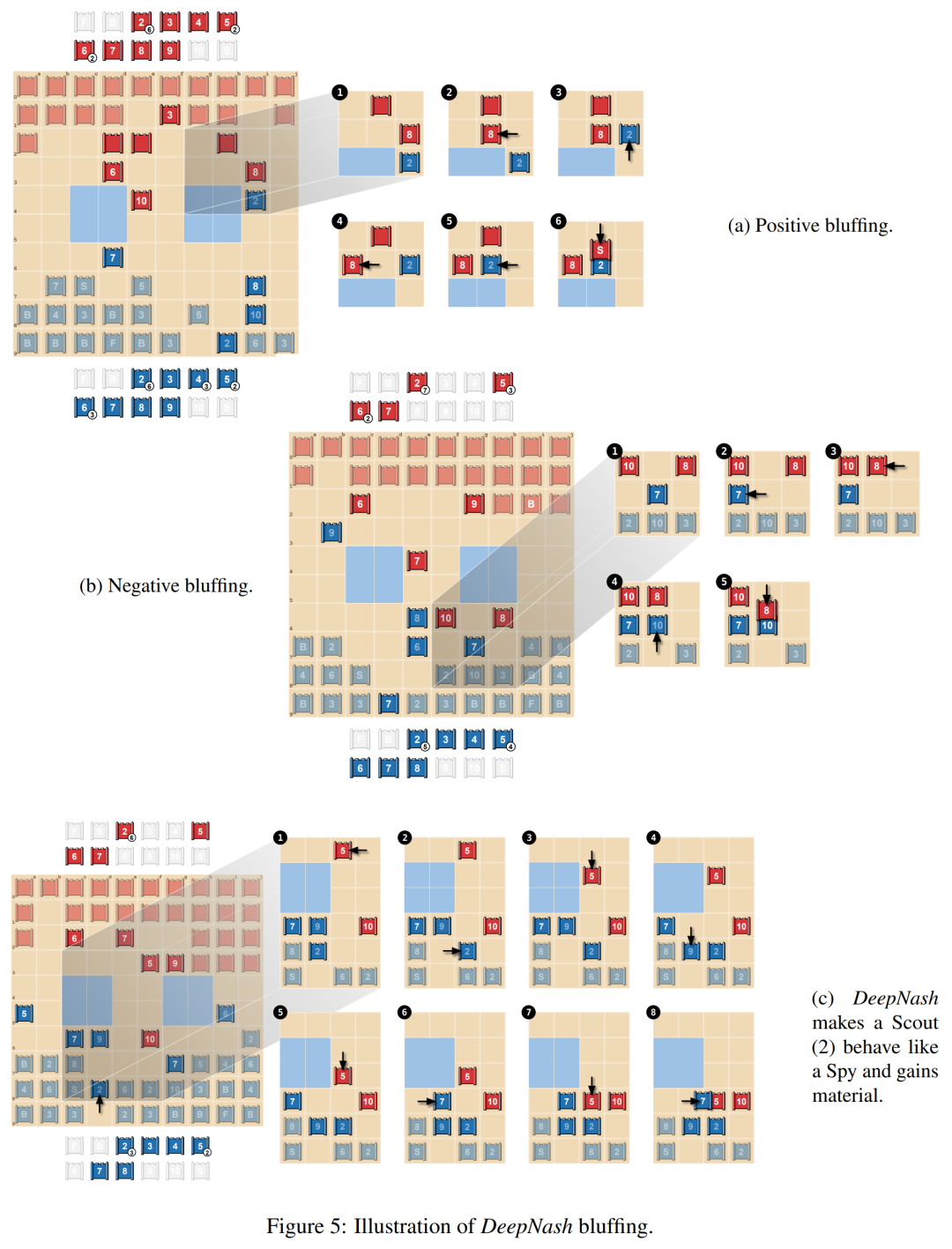
在下图5a中,研究者展示了积极的唬骗(positive bluffing),玩家假装棋子的价值高于实际价值。DeepNash用未知棋子Scout (2) 追逐对手的8,并假装它是10。对手认为这个棋子可能是10,将其引导至Spy旁边(可以捕获10)。但是,为了夺取这枚棋子,对手的Spy输给了DeepNash的Scout。
第二类唬骗为消极唬骗(negative bluffing),如下图5b所示。它与积极唬骗相反,玩家假装棋子的价值低于实际价值。
下图5c展示了一种更复杂的bluff,其中DeepNash将其未公开的Scout (2)接近对手的10,这可以被解释为Spy。这种策略实际上允许蓝方在几步之后用7捕获红方的5,因此获得material,阻止5捕获Scout (2),并揭示它实际上并不是Spy。
来源:机器之心
