图灵奖得主 Adi Shamir最新理论,揭秘对抗性样本奥秘
发布时间:2022-06-29
导读:为什么模型会将「猫」识别成「牛油果酱」,将「猪」识别成「飞机」?
要回答这个问题,就涉及到对抗性样本(Adversarial examples)。对抗性样本指在原始样本添加一些人眼无法察觉的扰动(这样的扰动不会影响人类的识别,但却很容易愚弄模型),致使机器做出错误的判断。
这一对安全影响重要的特征,到目前为止仍无很明确的解释。
进入深度学习时代,年逾花甲的图灵奖得主 Adi Shamir 带领团队踏上了对抗性样本的研究之旅。
在2022北京智源大会首日的特邀报告环节,Adi Shamir发表了题为「A New Theory of Adversarial Examples in Machine Learning」的主旨演讲,讲解了他最新发表的工作。在本次演讲中,Adi Shamir 教授提出了一种「凹槽流形」(dimpled manifold)解释了机器学习中对抗性样本的性质及其存在的原因,为我们理解深度神经网络的工作原理提供了全新的思路,对该领域具有开创性的意义。(注:本文由智源社区整理,未经本人审阅)
大约 9 年前开始,一些研究组发现神经网络很容易被「愚弄」,只要向输入图片进行极其微小的改变就可以让网络的决策结果彻底改变。由于深度神经网络在识别垃圾邮件、分析计算机网络的行为等涉及信息安全的领域被广泛使用,Adi Shamir 教授近年来也对对抗性样本和鲁棒深度学习产生了很大的研究兴趣。

对抗性样本的例子屡见不鲜。如上图所示,深度神经网络可以把左侧的图片正确识别为「猫」。然而,只要对图片施加微小改变,就可以让右侧对人类来说几乎一模一样的图片被网络以 99% 的置信度识别为「牛油果酱」。对人来说,右侧的图片与「牛油果酱」没有任何相似的地方,该图片大部分的地方是灰色的,而牛油果酱则是绿色;牛油果酱应该是光滑的,而此图有大量的纹理。研究者们尚不清楚出现这种现象背后的原因。

另举一例,在上图中,左侧图片中有一只猪。我们对图像施加及其微小的扰动(0.005 * 中间的扰动图)后,得到右侧的图像。尽管人类仍然看到了一只几乎一模一样的猪,但网络会将其识别为飞机。实际上,中间的扰动图类似于随机噪声,我们几乎完全无法看到其中包括机翼、机尾等部件。
针对对抗性样本存在的原因,现有许多研究给出的解释过于直观,例如:我们对高维空间缺乏很好的直觉;深度神经网络就有高度非线性的特性;深度神经网络具有局部的线性性质;训练数据量不足。此外,MIT 的研究者曾将对抗性样本的存在归结于图像所具备的鲁棒特征和非鲁棒特征。但上述解释都十分模糊和直观,并未从数学上给出令人信服的解释。
01 标准思维图景不足
Shamir认为不妨构建一种标注的思维图景来分析对抗性样本。如图所示,图中的每个数据点是一个完整的图像,红色的部分是猫图像的聚类簇,其中大多数图像可能是灰色的;蓝色部分是牛油果酱的聚类簇,其中大多数图像可能是绿色的。在本文中,为简单起见,只考虑 2 分类的情况,但是该理论同样也适用于多分类情况。
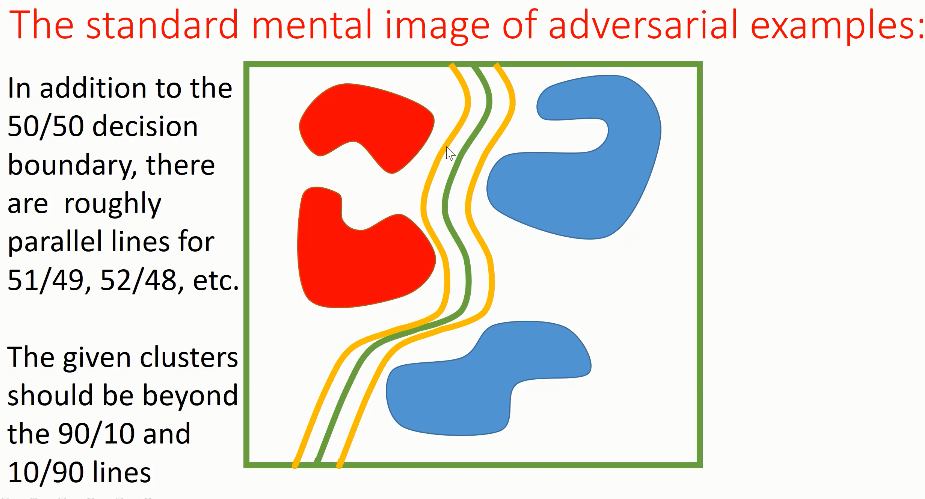
如果想要区分猫和牛油果的图像,可以构造如上图所示的绿色决策边界。该决策边界以 50%/50% 的置信度将猫和牛油果图像分隔于两侧,即无法确定决策边界上的点属于哪一类。
研究者将该决策边界扩展到各种其它的情况下,如图中黄色的决策边界:以 51%/49% 的置信度将图片分为猫/牛油果,或者反过来。

假设要根据红色簇中的猫图片构造对抗性样本,研究者通常会让图像特征沿着最陡峭的方向朝决策边界移动,跨越决策边界,直至以 99% 的置信度将图片分类为牛油果酱。从大多数红色的猫移动到大多数绿色的牛油果酱的距离较长,研究者可能需要对许多像素进行改变。Ian Goodfellow 认为,确实存在这种从猫的中心指向牛油果酱中心的扰动。
但如果仔细分析,这种思维图景给出的解释是没有意义的。面对对抗性样本的谜题,我们不禁要思考:
(1)这些看起来像猫但是被网络识别为牛油果酱的图像有何特别之处?它们与正常的光滑、绿色的牛油果酱完全不同。
(2)为什么在猫的图像周围的空间中,也存在汽车、飞机、船、马、青蛙等图像的表征?还有没有其它我们关心的对象?各种类别的图像在空间中混杂在一起,而我们期望在理想情况下每个类别的图像占据空间中集中的一块角落。
(3)为什么有的对抗性样本与原始图像距离很接近?极其微小的变化就会彻底改变网络的识别结果。
(4)为什么对抗性扰动与目标类并不相似?扰动往往并不具备与人类常识相符的语义。
所以,前文所述的标准对抗性样本思维图景与实际情况并不相符。随机的「猫」类别和像「牛油果酱」的类之间的平均距离摇臂实际的对抗性样本和原始样本的距离大得多。
02 新的理论——凹槽流形(dimpled manifold)
为此,Adi Shamir 提出了一种「凹槽流形」(dimpled manifold)理论。假设神经网络的输入是 n 维空间内的向量,向量每一个维度分别代表特定的语义,其值处于 0-1 之间。然而,所有的自然图像都位于嵌入在大的 n 维空间的低维流形上。这样的流形是十分光滑的,图像之间存在边界,局部流行之间的分布可能是非均匀的。流形对图像嵌入到整个输入空间中的方式给出了一些约束。相较于原始输入向量,自然图像可以以极小的质量损失被压缩到非常小的尺寸。
在缺乏对低维流形先验知识的情况下,深度神经网络试图在 n 维空间中生成(n-1)维的决策边界,从而将空间分成两个部分。决策边界不必一定连接在一起,可以分成若干段,决策边界的质量仅仅由其在 k 维图像流形上的性能决定(k 远小于 n)。
决策边界只需要在空间中的很小一部分上具有非常好的性能即可,在其它部分网络可以选择位于任意位置的决策边界,此时网络不必添加额外的惩罚。
此外,网络还可以利用额外的 n-k 个维度,从而使其在流形上的性能更好(例如,更好地描述猫和牛油果酱的图片)。Adi Shamir 认为,正是由于较小的 k 维图像流形和较大的 n 维空间之间的错误匹配导致了对抗性样本的产生。
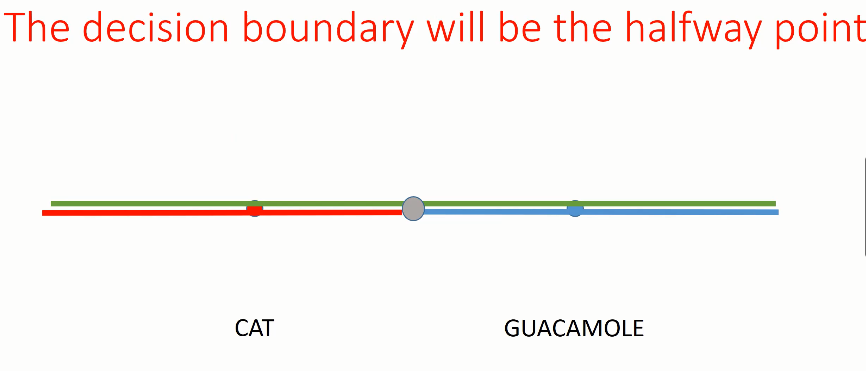
假设分别有一张猫的图像和一张牛油果酱的图像,它们处于绿色的一维流形上。神经网络选择了流形上大致位于两张图片正中间的点将两类区分开,该点左侧的点被分为猫,该点右侧的点被分为牛油果酱。
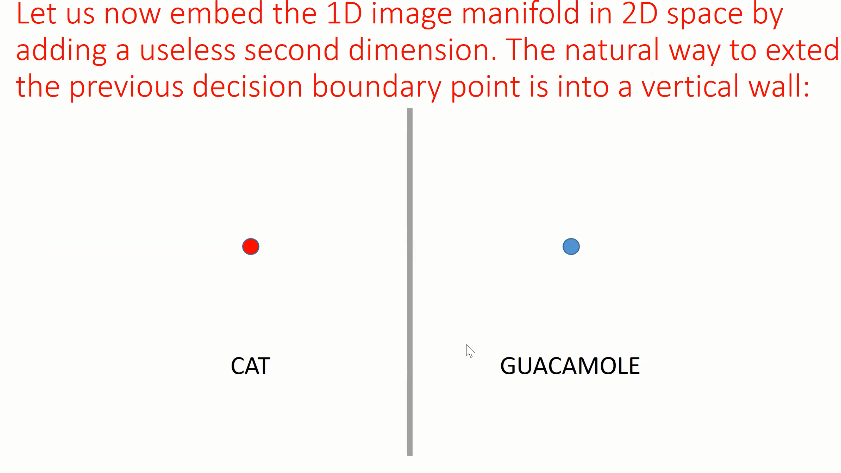
在前文所述的一维流形上,左侧平均可能是灰色的图像,右侧平均可能是绿色的图像,网络以此来确定图像之间的差别。如上图所示,我们额外加入了一个「无用」的维度,将数据点嵌入到二维空间中,从而更好地区分猫和牛油果酱,其决策边界可能是一条垂直的线。实际上,这样等价的决策边界并不唯一,它们都可以在流形上区分猫和牛油果酱。
03 Claim 1:网络训练后会得到流形的凹陷版本
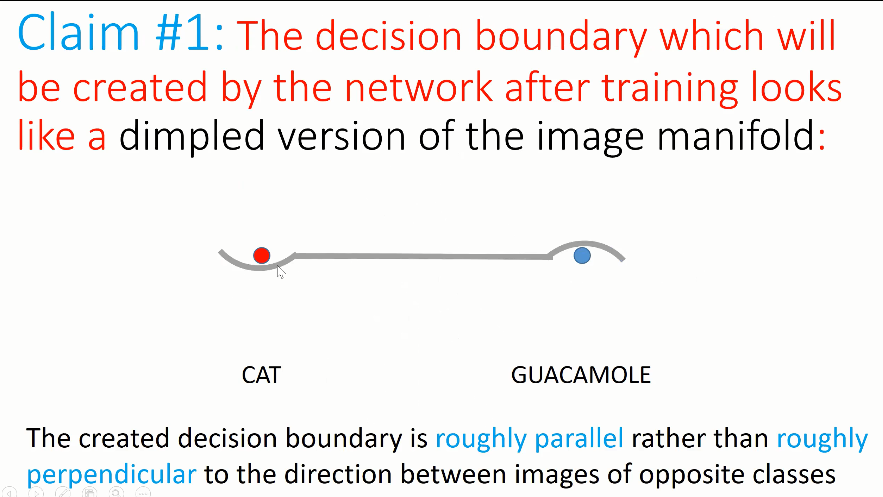
Adi Shamir 认为,当我们考虑更多的猫、牛油果酱的图片时,网络经过训练后创建的决策边界就好像在图像流形上引入了一些「凹槽」。决策边界的大部分非常接近图像流形,但是在猫的图像的下方创建了一个小的凹槽,而在牛油果酱图像的上方创建了一个小的突凸起。
由此,在与红色的点位于决策边界相同一侧的点被识别为猫,与蓝色点位于相同一侧的点则被识别为牛油果酱。因此,此时的决策边界并不再垂直于图像流形,而是几乎与流形平行,并且具有一些小的凸起或凹槽,从而将某些点纳入决策边界正确的一侧。

如上图所示,中间扁平的表面是二维流形,黄色的点代表猫,蓝色的点代表牛油果酱。Adi Shamir 认为,神经网络选择的决策边界会选择扁平的、与图像流形接近的决策边界。在猫的图像处,决策边界向下凹陷,在牛油果酱图像处,决策边界向上凸起。
04 Claim 2:粘附与凹陷
Adi Shamir 认为,网络的训练由 2 个连续的阶段组成。在第一个阶段,网络在训练早期的若干 epoch 上不过多考虑标签,快速地让决策边界靠近图像流形。接着,在第二个阶段,网络重点关注训练样本的标签,此时决策边界开始产生一些凹槽,从而调整决策边界的形状细节。同时,随机初始化的深度神经网络在第一个 epoch 之前拥有一个方向随机的初始决策边界。
由于无法可视化非常高维的空间,在本文中考虑以下 3 种实验设置:
(1)2D 空间中的 1D 图像流形,具有 1D 决策边界
(2)3D 空间中的 2D 图像流形,具有 2D 决策边界
(3)3D 空间中的 1D 图像流形,具有 2D 决策边界
实验 1:2D 空间中的 1D 流形

假设 1D 图像流形是 2D 空间正中间的直线,网络需要学习一个将红点和蓝点分隔开的决策边界。初始状态下决策边界的朝向是随机的,在第 10 个 epoch 时,决策边界开始靠近图像流形;在第 20 个 epoch 时,它与图像流形更加接近;到了第 30 个 epoch,决策边界与图像流形的重合度就很高了;直到第 100 个 epoch,决策边界用一些小的凹槽和凸起很好地「包络」了数据点,红点在决策边界上方,而蓝点在决策边界下方。
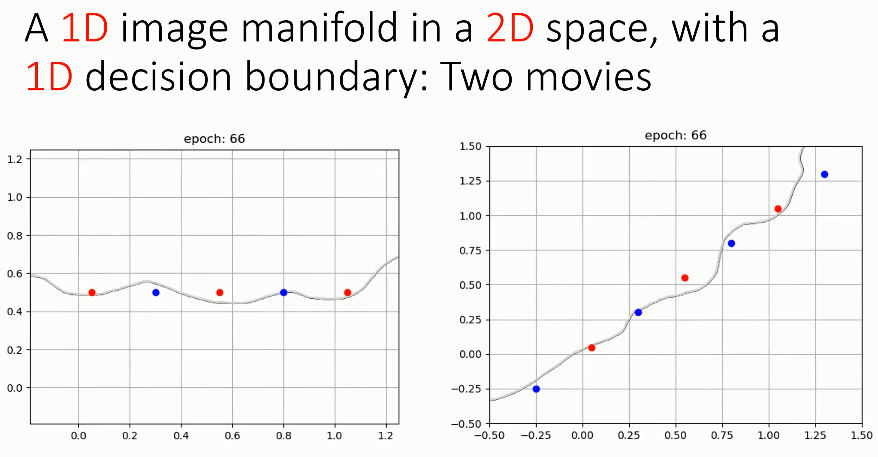
如上图所示,当 1D 图像流形为对角线形状时,神经网络学习到的决策边界的变化情况也与水平 1D 流形类似,决策边界一开始会接近图像流形,随后根据图像标签进行微调,用凸起或凹槽包络数据点,使其标签与决策边界相符。
实验 2:3D 空间中的 2D 图像流形
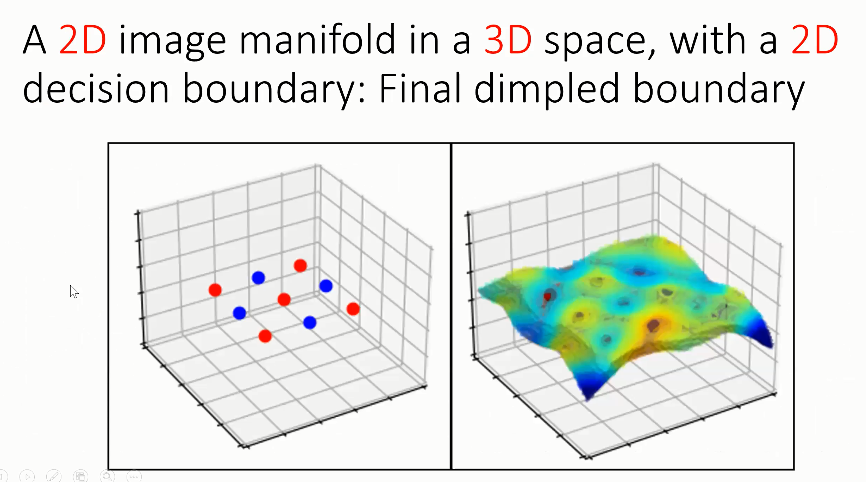
考虑如上图所示的 3D 空间中的 2D 流形,该流形接近扁平的水平面。对红色和蓝色的模式来说,它们排列在同一个 2D 平面上,具有相同的 Z 值,因此 Z 维度对流形没有意义。然而,Z 维度可以帮助网络构造决策边界的凸起和凹槽形状,从而区分开红点和蓝点。这个决策边界与「等高线」类似,其中棕红色部分为山峰,而蓝色部分为盆地。

决策边界在训练时的演化过程如上图所示。初始状态下决策边界是随机的,此时与图像流形和标签都无关。接着,决策边界逐渐接近图像流形。然后,决策边界产生了凸起和凹槽,此时红色点在决策边界下方,而蓝色点在决策边界上方。
实验 3:3D 空间中的 1D 图像流形
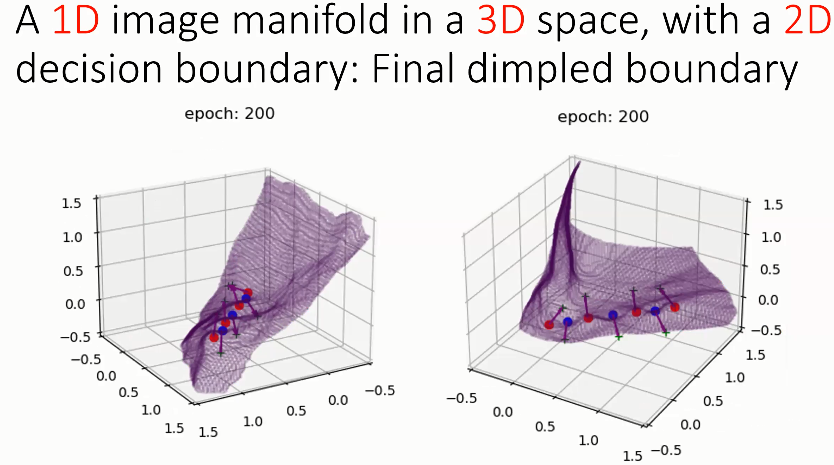
如上图所示,对于 3D 空间中的 1D 流形,研究者考虑用 2D 的决策边界区分各类数据点的情况。观察图像流形周围的部分,发现决策边界通过波浪形的线试图将所有红点包络在边界下方,将蓝点包络在边界上方。
凹槽流形产生的原因
直观地说,假设流形上散落着许多蓝色和红色的点,分别代表牛油果酱图像和猫的图像。对于随机初始化的深度神经网络而言,决策边界在 n 维空间中的方向也是随机的。初始情况下,决策边界并不能很好地区分两类数据点,但是可以移动决策边界进行调整。可以将决策边界想象成打印纸,将其弯曲成想要的形状。
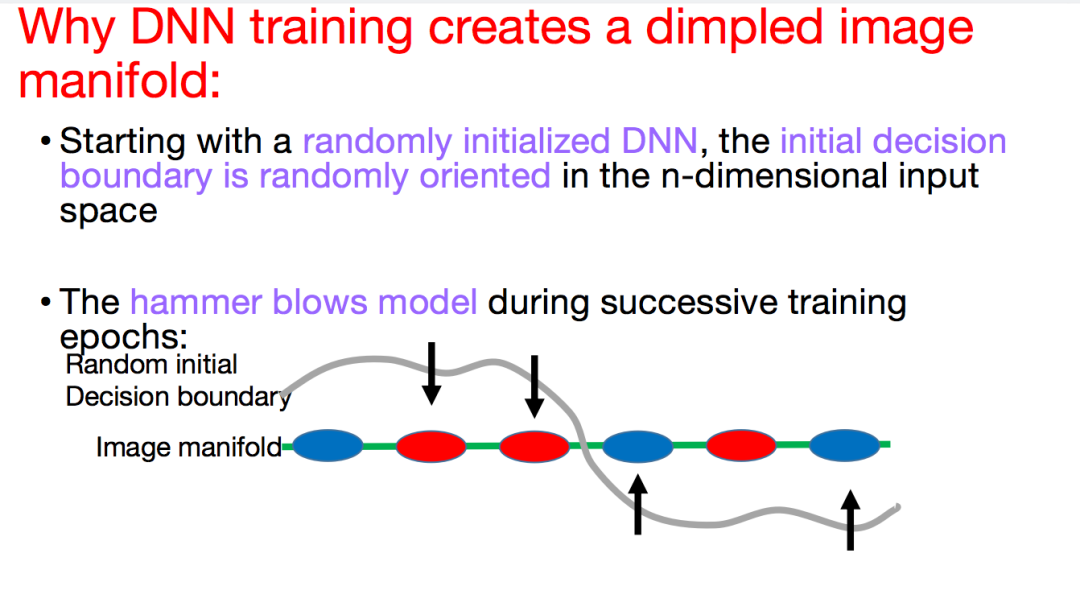
在联系的训练过程中,研究者可以在每个 epoch 上建立「锤击模型」。假设红色的点应该处于决策边界上方,而蓝色的点应该处于决策边界下方。在不符合数据点要求的位置,有力量将决策边界向理想状态牵引。如上图所示,在左侧的两个红色数据点处,决策边界会受到向下的牵引力;在右侧的两个蓝色数据点处,决策边界会受到向上的牵引力。
值得一提的是,这种牵引力会作用于数据点周围的区域,而不是仅仅作用于数据点的局部。所有的牵引力试图利用不符合理想情况的数据点,将随机初始化的决策边界在训练初期的数个 epoch 中快速朝着图像流形移动。
05 claim 3:对抗性扰动的方向大致垂直于图像流形
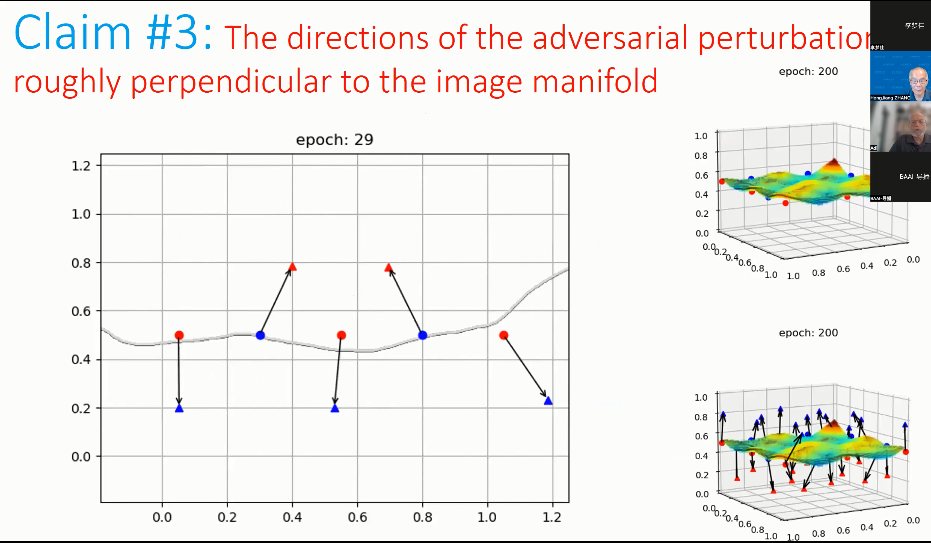
在训练过程中,对抗性扰动演化的方向大致垂直于图像流形。初始状态下,决策边界位置是随机的。随着决策边界逐渐贴近图像流形并生成一些凸起和凹槽,一些对抗性样本试图朝着决策边界的另一侧的方向移动。
这些点移动的方向并不是从某一类的中心指向另一类的中心,而是朝着完全不相同的、垂直于局部图像流形的方向移动。因此,随着训练的演化,这些点的移动方向也在变化。
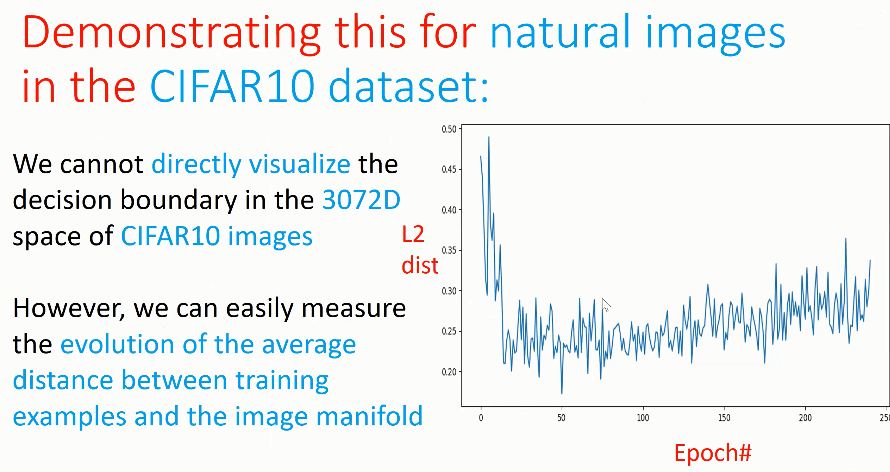
如上图所示,对于 CIFAR10 数据集上的自然图像来说,研究者无法直接可视化 3,072 维空间中的决策边界,但是可以度量训练样本和图像流形之间的平均距离的演化情况。
初始状态下的平均距离非常大,但是经过初期的少数几个 epoch 的训练后,决策边界迅速贴近图像流形,距离迅速减小;接着给定的训练样本开始帮助决策边界产生凸起和凹槽,这个训练阶段就相对较慢,平均距离可能会稍微增加。
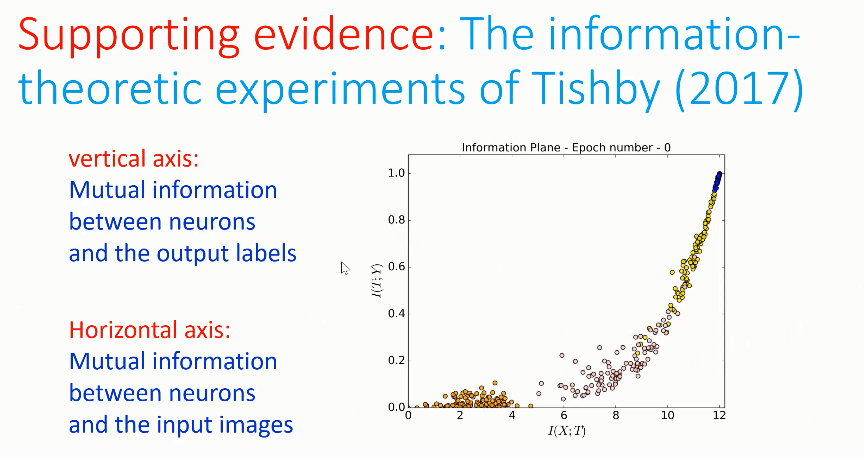
2017 年,Tishby 等人从信息论的角度设计实验证明了上述观点,观察了神经网络的权重向量与输入图像、输出标签之间的互信息。如上图所示,横轴为神经元与输入图像之间的互信息,纵轴为神经元与输出标签之间的互信息。

图中的点也在训练过程中展现出了一种 2 阶段的性质:起初,图中的点向右移动,这代表网络利用了更多关于训练样本的输入位置的信息,决策边界向着图像流形移动;接着,这些点突然改变方向,向左上方移动,这代表网络利用了更多关于图像标签的信息,决策边界产生了凸起和凹槽。在第二个阶段,网络权重与输出之间的互信息加大,并且遗忘了部分已知的关于输入位置的信息。
06 Claim 4:网络训练倾向于产生大的梯度
Adi Shamir 指出,在训练过程中,网络倾向于朝着图像流形产生大的梯度。图像流形相对来说十分扁平,在大多数地方十分扁平,并且具有一些较为和谐的边缘,而流形往往不会剧烈变化。较小的梯度会使决策边界在训练样本处产生距离很远的凸起或凹槽,难以适应于周围训练样本标签的冲突,从而导致网络的准确率较低。而当梯度较大时,决策边界只需要移动较小的距离即可对网络决策产生很大的影响。
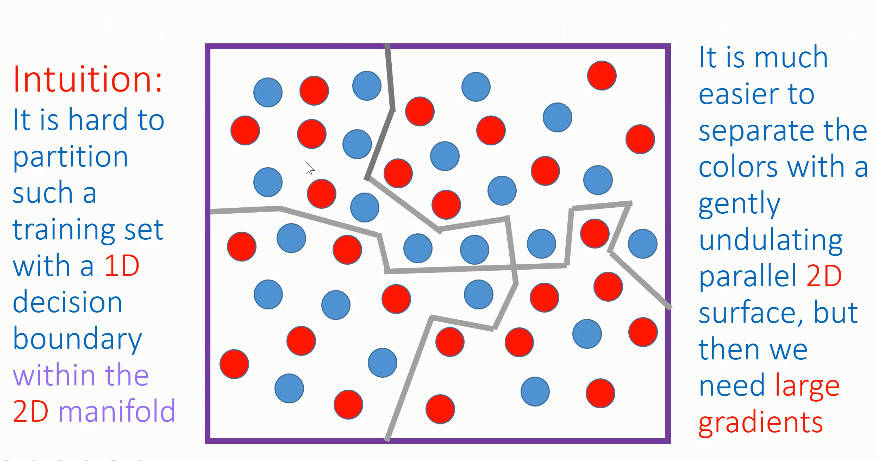
网络在训练过程中会很快地靠近图像流形,并且产生较小的凹槽,将混合在一起的图像区分开来。如上图所示,在 2D 图像流形中,很难通过 1D 决策边界区分红色和蓝色的点,尤其是在凸起处。但是,如果引入第三个维度(假设垂直于屏幕)就可以很容易地创建决策边界,通过较小的垂直的凸起来区分各类点,此时的梯度较大。

在 Adi Shamir 构建的模型中,便捷的网络训练和对于对抗攻击的敏感性是一枚硬币的两面。在训练网络时,我们将数据点固定,移动决策边界,从而将数据点置于正确的一侧。在创建对抗性样本时,我们将决策边界固定,沿着梯度较大的方向移动数据点,这样可以很快将数据点从以 90% 置信度将图片分为猫的位置移动到模棱两可的决策边界,进而移动到以 90% 置信度将图像分为牛油果酱的位置。
07 对抗性样本背后的奥秘
通过 Adi Shamir 构建的模型,可以很直观、清晰地解释对抗性样本。在他看来,我们可以得到以下几点启示:
(1)对抗性样本并不是从属于其它类别的真实图像,它们只是通过垂直地将数据点向着图像流形移动得到的「伪图像」。在猫和牛油果酱的例子中,真实的绿色的牛油果酱只占据图像流形上很少的一部分。然而,在距离灰色的猫很近的区域里,决策边界的另一侧全都是「伪-牛油果酱」的空间,这部分的图像往往并不具有牛油果酱的图像特征。对于多分类任务,网络通过向着不同类的垂直方向移动数据点,得到对抗性样本。
(2)在通过对抗性攻击将猫的图像变为牛油果酱时,扰动的 L2 范数往往很小。这是因为垂直方向有最大的梯度,可以以最小的距离让网络决策完全改变。
(3)在使用对抗性攻击使网络将猫分类为牛油果酱时,对抗性扰动看上去并不具有牛油果酱的图像特征。假设流形为简单的![]() ,我们在垂直方向随机选择一个单位向量
,我们在垂直方向随机选择一个单位向量![]() ,其中每一个非零项服从正态分布,其值大致位于
,其中每一个非零项服从正态分布,其值大致位于![]() 的区间内。这样一来,扰动图就近似于随机噪声,我们并不会看到任何其它类的特征。
的区间内。这样一来,扰动图就近似于随机噪声,我们并不会看到任何其它类的特征。
08 小结
将为了得到对抗性样本,旧的思维图景假设我们将图像朝着另一个类移动很远的距离,而凹槽流形理论假设我们只需将图像沿着垂直于流形的方向移动很短的距离。此外,旧的思维图景认为对抗性样本是图像流形上的真实图像,而凹槽流形理论认为对抗性样本是图像流形外的伪图像,他们不需要具备某类图形的特征。
09 通过对抗性训练增强网络鲁棒性
进行常规训练时,可以得到带有凹槽的决策边界。如果进行对抗性训练,网络首先会生成被错误分类为牛油果酱的对抗性样本,这会进一步强制让网络记住这些对抗性样本仍然是猫。这样一来就可以得到具有更深的凹槽的决策边界。

10 破解对抗性机器学习之谜
2019 年,Madry 等人进行了一项神奇的实验。他们仅仅利用带有错误标签的对抗性样本训练网络。尽管网络在整个训练过程中从未看到过带有猫标签的、与猫外形类似的图像,但是在测试时却可以正确地对很大一部分猫的图像进行分类。
具体而言,在该实验中,Madry 等人首先用训练集![]() 中的图像训练了一个深度神经网络 N1,该网络以很高的准确率将猫和牛油果酱区分开。接着,他们使用 N1 构造训练样本
中的图像训练了一个深度神经网络 N1,该网络以很高的准确率将猫和牛油果酱区分开。接着,他们使用 N1 构造训练样本![]() 的对抗性样本
的对抗性样本![]() 。最后,他们仅仅使用对抗性样本来训练一个新的深度神经网络 N2,该网络可能与 N1 的架构、尺寸、初始化方式完全不同,
。最后,他们仅仅使用对抗性样本来训练一个新的深度神经网络 N2,该网络可能与 N1 的架构、尺寸、初始化方式完全不同,![]() 具有错误的类别标签。然而,N2 仍然能够很准确地对猫进行正确分类。
具有错误的类别标签。然而,N2 仍然能够很准确地对猫进行正确分类。

为此 Adi Shamir 给出了如上图所示的解释。在该图中,C 代表猫的图像,G 代表牛油果酱图像,他们分布于水平的图像流形上,红色的折线代表 N1 网络的决策边界。决策边界在数据点上与流形的距离为![]() 。
。
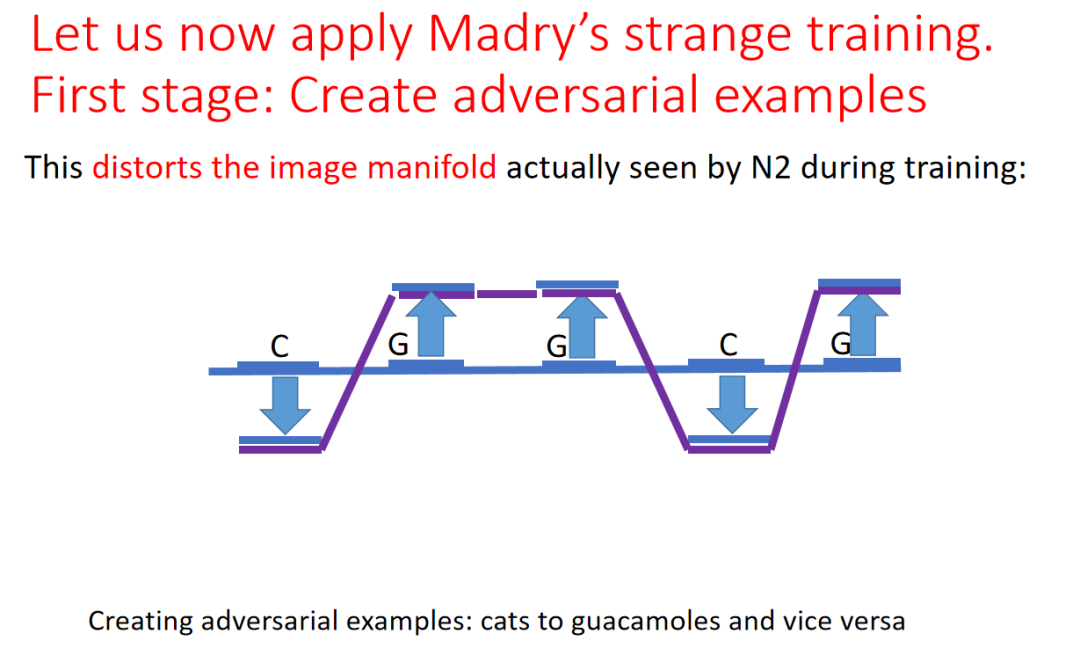
在构造对抗性样本时,研究者将原始图像朝着与决策边界垂直的方向移动 2![]() 的距离,跨过原始的红色决策边界,得到了如上图所示的紫色流形。研究者仅仅利用新的对抗性样本训练 N2,不会让其看到原始的图像。在训练过程中,决策边界首先会贴近新的流形。
的距离,跨过原始的红色决策边界,得到了如上图所示的紫色流形。研究者仅仅利用新的对抗性样本训练 N2,不会让其看到原始的图像。在训练过程中,决策边界首先会贴近新的流形。
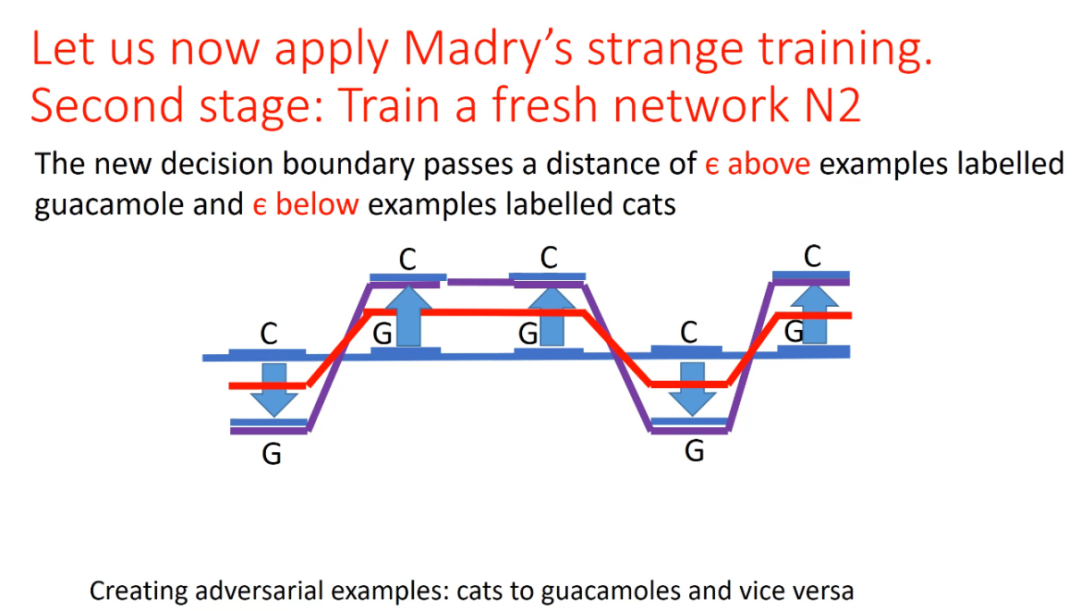
接着,网络利用研究者给出的反转后的错误标签进一步调整决策边界,使其产生凹槽和突起,得到了上图中红色的新决策边界。此时,这条新的红色边界与初始的 N1 的决策边界相同。上述过程相当于一种「否定之否定」,最后得到了与初始情况相同的结果。因此,N2 可以正确地识别猫和牛油果酱。该实验也证明了「凹槽流形」理论的正确性。
来源:智源社区
