CVPR 2022 最新106篇论文分方向整理|包含目标检测、动作识别、图像处理等32个方向
发布时间:2022-03-22CVPR 2022 已经放榜,本次一共有2067篇论文被接收,接收论文数量相比去年增长了24%。在CVPR2022正式会议召开前,为了让大家更快地获取和学习到计算机视觉前沿技术,极市对CVPR022 最新论文进行追踪,包括分研究方向的论文、代码汇总以及论文技术直播分享。
CVPR 2022 论文分方向整理目前在极市社区持续更新中,已累计更新了254篇,项目地址:https://bbs.cvmart.net/articles/6124
以下是本周更新的 CVPR 2022 论文,包含包含目标检测、图像处理、三维视觉、医学影像、视频检索等方向。
分类目录:
n 检测类
n 2D目标检测
n 3D目标检测
n 伪装目标检测
n 显著性目标检测
n 边缘检测
n 消失点检测
n 分割类
n 图像分割
n 语义分割
n 视频目标分割
n 人脸
n 人脸生成
n 人脸检测
n 图像处理
n 图像复原
n 图像编辑/图像修复
n 图像翻译
n 超分辨率
n 去噪/去模糊/去雨去雾
n 风格迁移
n 三维视觉
n 三维重建
n 场景重建/视图合成
n 点云
n 神经网络架构设计
n CNN
n Transformer
n MLP
n 神经网络架构搜索
n 人体解析/人体姿态估计
n 动作识别/检测
n 视觉定位/位姿估计
n 光流/运动估计
n 医学影像
n 文本理解
n GAN/生成式/对抗式
n 视频检索
n 图像&视频生成/合成
n 视觉推理/视觉问答
n 视觉预测
n 图像计数
n 机器人
n 多模态学习
n 视觉-语言
n 自监督/半监督/无监督学习
n 联邦学习
n 度量学习
n 增量学习
n 迁移学习/domain/自适应
n 对比学习
n 主动学习
n 数据处理
n 图像压缩
n 图像聚类
n 视觉表征学习
n 模型训练/泛化
n 噪声标签
n 模型压缩
n 知识蒸馏
n 剪枝
n 量化
n 数据集
01 检测类
2D目标检测
[1] MUM : Mix Image Tiles and UnMix Feature Tiles for Semi-Supervised Object Detection(混合图像块和 UnMix 特征块用于半监督目标检测)
paper:https://arxiv.org/abs/2111.10958
code:https://github.com/JongMokKim/mix-unmix
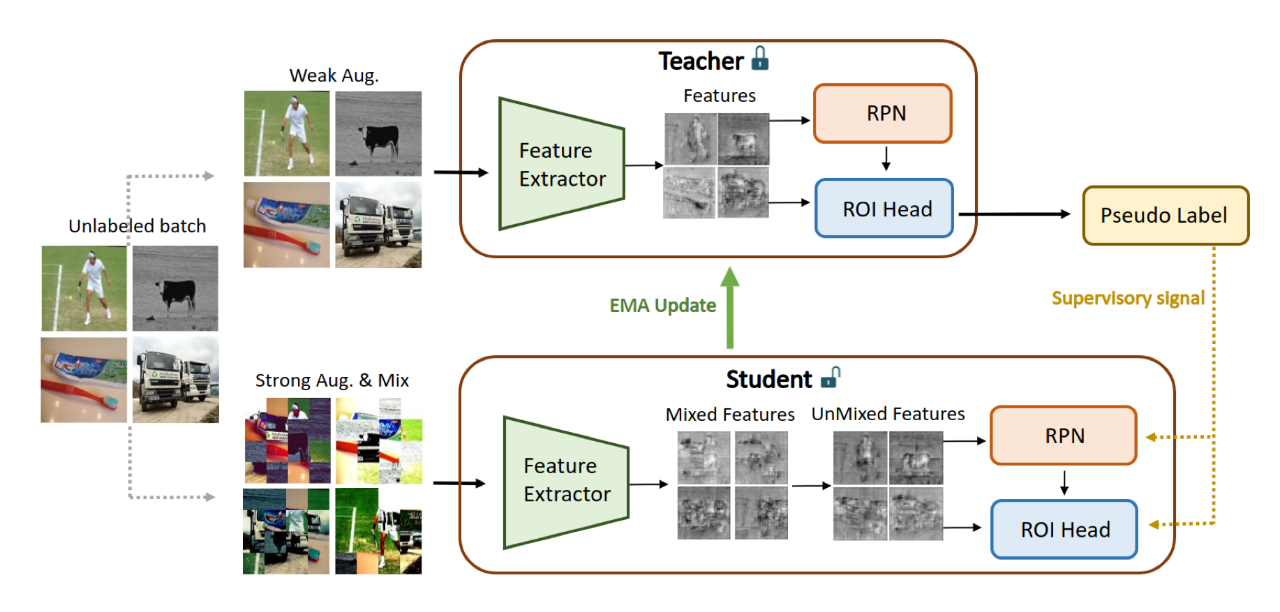
[2] SIGMA: Semantic-complete Graph Matching for Domain Adaptive Object Detection(域自适应对象检测的语义完全图匹配)
paper:https://arxiv.org/abs/2203.06398
code:https://github.com/CityU-AIM-Group/SIGMA
[3] Accelerating DETR Convergence via Semantic-Aligned Matching(通过语义对齐匹配加速 DETR 收敛)
paper:https://arxiv.org/abs/2203.06883
code:https://github.com/ZhangGongjie/SAM-DETR
3D目标检测
[1] MonoJSG: Joint Semantic and Geometric Cost Volume for Monocular 3D Object Detection(单目 3D 目标检测的联合语义和几何成本量)
paper:https://arxiv.org/abs/2203.08563
code:https://github.com/lianqing11/MonoJSG
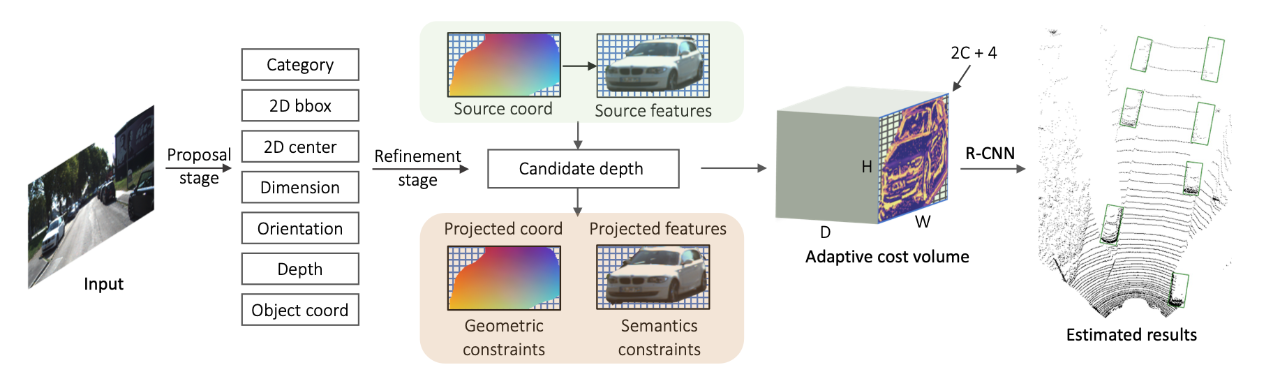
[2] DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection(用于多模态 3D 目标检测的激光雷达相机深度融合)
paper:https://arxiv.org/abs/2203.08195
code:https://github.com/tensorflow/lingvo/tree/master/lingvo/
[3] Point Density-Aware Voxels for LiDAR 3D Object Detection(用于 LiDAR 3D 对象检测的点密度感知体素)
paper:https://arxiv.org/abs/2203.05662
code:https://github.com/TRAILab/PDV
伪装目标检测
[1] Implicit Motion Handling for Video Camouflaged Object Detection(视频伪装对象检测的隐式运动处理)
paper:https://arxiv.org/abs/2203.07363
dataset:https://xueliancheng.github.io/SLT-Net-project
显著性目标检测
[1] Bi-directional Object-context Prioritization Learning for Saliency Ranking(显著性排名的双向对象上下文优先级学习)
paper:https://arxiv.org/abs/2203.09416
code:https://github.com/GrassBro/OCOR

[2] Democracy Does Matter: Comprehensive Feature Mining for Co-Salient Object Detection(共同显著性目标检测的综合特征挖掘)
paper:https://arxiv.org/abs/2203.05787
边缘检测
[1] EDTER: Edge Detection with Transformer(使用transformer的边缘检测)
paper:https://arxiv.org/abs/2203.08566
消失点检测
[1] Deep vanishing point detection: Geometric priors make dataset variations vanish(深度消失点检测:几何先验使数据集变化消失)
paper:https://arxiv.org/abs/2203.08586
code:https://github.com/yanconglin/VanishingPoint_HoughTransform_GaussianSphere
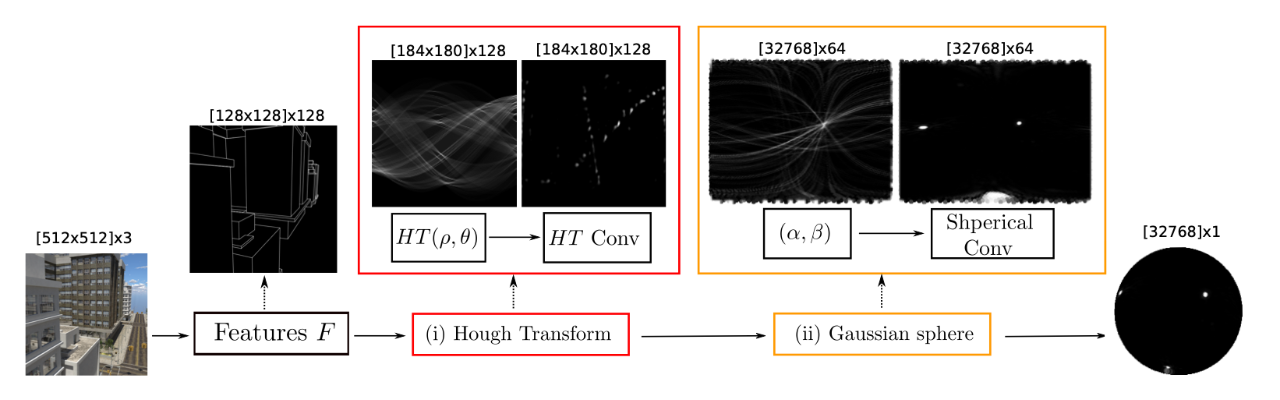
02 分割类
图像分割
[1] Learning What Not to Segment: A New Perspective on Few-Shot Segmentation(学习不分割的内容:关于小样本分割的新视角)
paper:https://arxiv.org/abs/2203.07615
code:http://github.com/chunbolang/BAM
[2] CRIS: CLIP-Driven Referring Image Segmentation(CLIP 驱动的参考图像分割)
paper:https://arxiv.org/abs/2111.15174
[3] Hyperbolic Image Segmentation(双曲线图像分割)
paper:https://arxiv.org/abs/2203.05898
语义分割
[1] Scribble-Supervised LiDAR Semantic Segmentation
paper:https://arxiv.org/abs/2203.08537
code:http://github.com/ouenal/scribblekitti
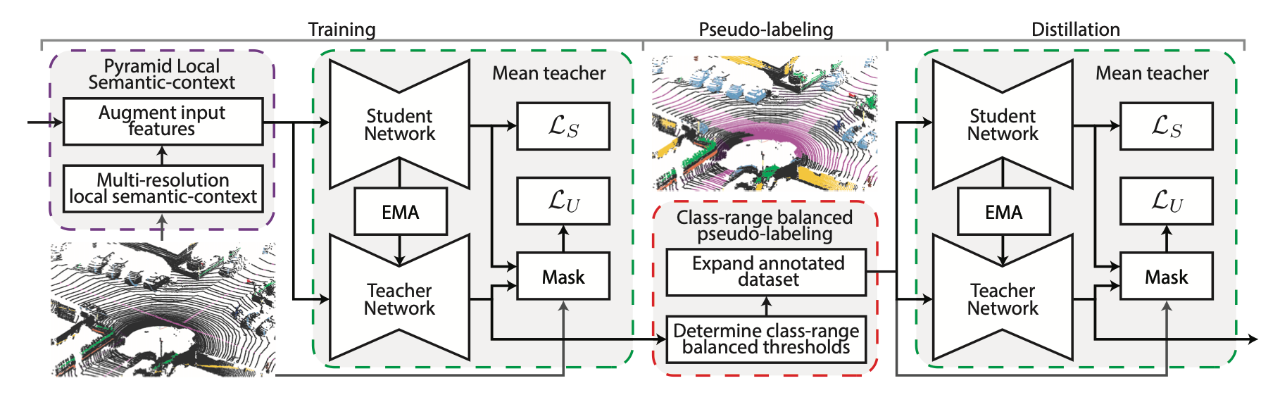
[2] ADAS: A Direct Adaptation Strategy for Multi-Target Domain Adaptive Semantic Segmentation(多目标域自适应语义分割的直接适应策略)
paper:https://arxiv.org/abs/2203.06811
[3] Weakly Supervised Semantic Segmentation by Pixel-to-Prototype Contrast(通过像素到原型对比的弱监督语义分割)
paper:https://arxiv.org/abs/2110.07110
视频目标分割
[1] Language as Queries for Referring Video Object Segmentation(语言作为引用视频对象分割的查询)
paper:https://arxiv.org/abs/2201.00487
code:https://github.com/wjn922/ReferFormer
03 人脸
[1] FaceFormer: Speech-Driven 3D Facial Animation with Transformers(FaceFormer:带有transformer的语音驱动的 3D 面部动画)
paper:https://arxiv.org/abs/2112.05329
code:https://evelynfan.github.io/audio2face/
[2] Sparse Local Patch Transformer for Robust Face Alignment and Landmarks Inherent Relation Learning(用于鲁棒人脸对齐和地标固有关系学习的稀疏局部补丁transformer)
paper:https://arxiv.org/abs/2203.06541
code:https://github.com/Jiahao-UTS/SLPT-master
人脸生成
[1] GCFSR: a Generative and Controllable Face Super Resolution Method Without Facial and GAN Priors(一种没有面部和 GAN 先验的生成可控人脸超分辨率方法)
paper:https://arxiv.org/abs/2203.07319
人脸检测
[1] Privacy-preserving Online AutoML for Domain-Specific Face Detection(用于特定领域人脸检测的隐私保护在线 AutoML)
paper:https://arxiv.org/abs/2203.08399

04 图像处理
图像复原
[1] Restormer: Efficient Transformer for High-Resolution Image Restoration(用于高分辨率图像复原的高效transformer)
paper:https://arxiv.org/abs/2111.09881
code:https://github.com/swz30/Restormer
图像编辑/图像修复
[1] High-Fidelity GAN Inversion for Image Attribute Editing(用于图像属性编辑的高保真 GAN 反演)
paper:https://arxiv.org/abs/2109.06590
code:https://github.com/Tengfei-Wang/HFGI
project:https://tengfei-wang.github.io/HFGI/
[2] Style Transformer for Image Inversion and Editing(用于图像反转和编辑的样式transformer)
paper:https://arxiv.org/abs/2203.07932
code:https://github.com/sapphire497/style-transformer
[3] MISF: Multi-level Interactive Siamese Filtering for High-Fidelity Image Inpainting(用于高保真图像修复的多级交互式 Siamese 过滤)
paper:https://arxiv.org/abs/2203.06304
code:https://github.com/tsingqguo/misf
图像翻译
[1] QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation(图像翻译中对比学习的查询选择注意)
paper:https://arxiv.org/abs/2203.08483
code:https://github.com/sapphire497/query-selected-attention
超分辨率
[1] A Text Attention Network for Spatial Deformation Robust Scene Text Image Super-resolution(一种用于空间变形鲁棒场景文本图像超分辨率的文本注意网络)
paper:https://arxiv.org/abs/2203.09388
code:https://github.com/mjq11302010044/TATT
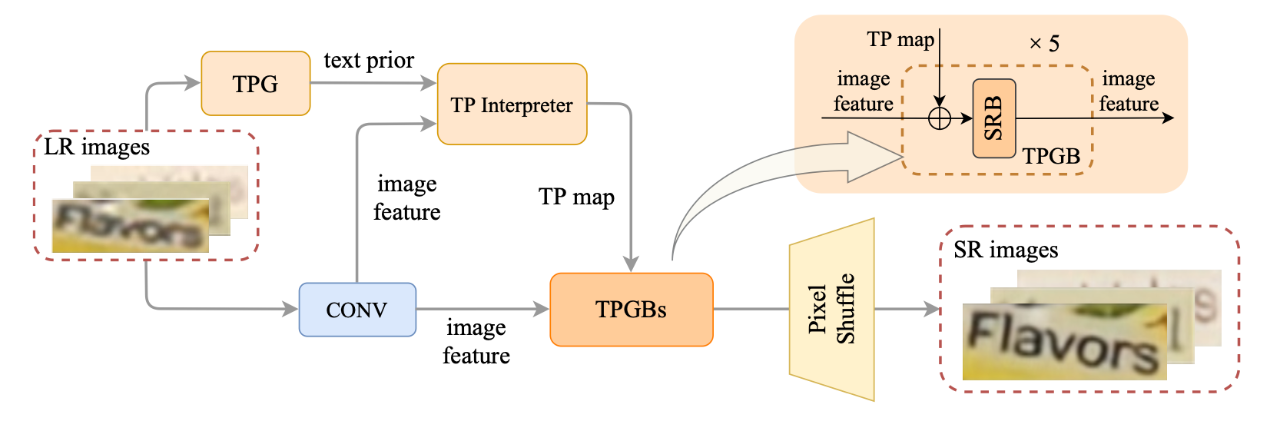
[2] Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution(一种真实图像超分辨率的局部判别学习方法)
paper:https://arxiv.org/abs/2203.09195
code:https://github.com/csjliang/LDL
[3] Blind Image Super-resolution with Elaborate Degradation Modeling on Noise and Kernel(对噪声和核进行精细退化建模的盲图像超分辨率)
paper:https://arxiv.org/abs/2107.00986
code:https://github.com/zsyOAOA/BSRDM
去噪/去模糊/去雨去雾
[1] Neural Compression-Based Feature Learning for Video Restoration(用于视频复原的基于神经压缩的特征学习)(视频处理)
paper:https://arxiv.org/abs/2203.09208
[2] Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots(具有可见盲点的自监督图像去噪)
paper:https://arxiv.org/abs/2203.06967
code:https://github.com/demonsjin/Blind2Unblind
风格迁移
[1] Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization(任意风格迁移和域泛化的精确特征分布匹配)
paper:https://arxiv.org/abs/2203.07740
code:https://github.com/YBZh/EFDM
05 三维视觉
三维重建
[1] AutoSDF: Shape Priors for 3D Completion, Reconstruction and Generation(用于 3D 完成、重建和生成的形状先验)
paper:https://arxiv.org/abs/2203.09516
project:https://yccyenchicheng.github.io/AutoSDF/
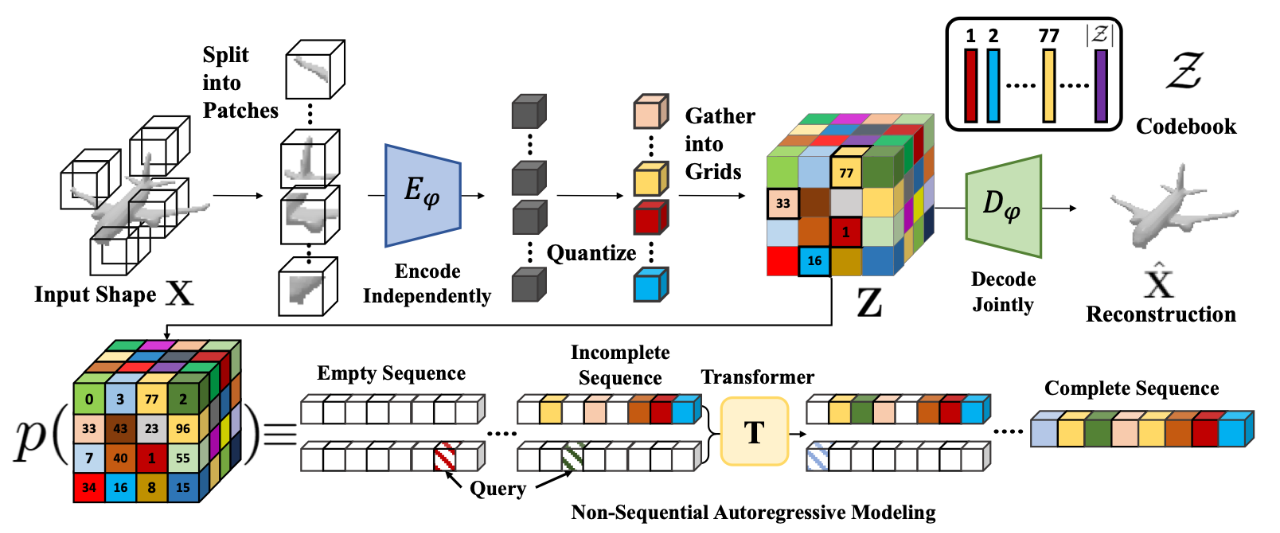
[2] Interacting Attention Graph for Single Image Two-Hand Reconstruction(单幅图像双手重建的交互注意力图)
paper:https://arxiv.org/abs/2203.09364
code:https://github.com/Dw1010/IntagHand
[3] OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction(实时动态 3D 重建的遮挡感知运动估计)
paper:https://arxiv.org/abs/2203.07977
project:https://wenbin-lin.github.io/OcclusionFusion
[4] Neural RGB-D Surface Reconstruction(神经 RGB-D 表面重建)
paper:https://arxiv.org/abs/2104.04532
project:https://dazinovic.github.io/neural-rgbd-surface-reconstruction/
video:https://youtu.be/iWuSowPsC3g
场景重建/视图合成
[1] StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions(室内 3D 场景重建的风格转换)
paper:https://arxiv.org/abs/2112.01530
code:https://github.com/lukasHoel/stylemesh
project:https://lukashoel.github.io/stylemesh/
[2] Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image(从单个图像合成一致的长期 3D 场景视频)
paper:https://arxiv.org/abs/2203.09457
code:https://github.com/xrenaa/Look-Outside-Room
project:https://xrenaa.github.io/look-outside-room/
点云
[1] AutoGPart: Intermediate Supervision Search for Generalizable 3D Part Segmentation(通用 3D 零件分割的中间监督搜索)
paper:https://arxiv.org/abs/2203.06558
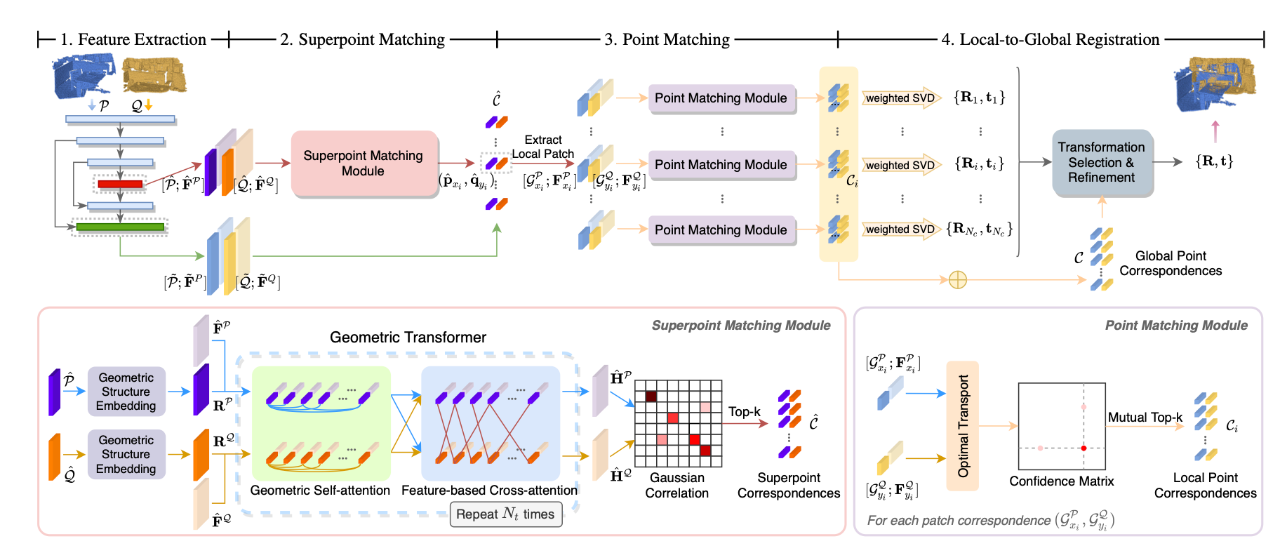
[2] Geometric Transformer for Fast and Robust Point Cloud Registration(用于快速和稳健点云配准的几何transformer)
paper:https://arxiv.org/abs/2202.06688
code:https://github.com/qinzheng93/GeoTransformer
06 神经网络架构设计
CNN
[1] On the Integration of Self-Attention and Convolution(自注意力和卷积的整合)
paper:https://arxiv.org/abs/2111.14556
code1:https://github.com/LeapLabTHU/ACmix
code2:https://gitee.com/mindspore/models
[2] Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs(将内核扩展到 31x31:重新审视 CNN 中的大型内核设计)
paper:https://arxiv.org/abs/2203.06717
code:https://github.com/megvii-research/RepLKNet)
解读:凭什么 31x31 大小卷积核的耗时可以和 9x9 卷积差不多?
Transformer
[1] Attribute Surrogates Learning and Spectral Tokens Pooling in Transformers for Few-shot Learning
paper:https://arxiv.org/abs/2203.09064
code:https://github.com/StomachCold/HCTransformers
[2] NomMer: Nominate Synergistic Context in Vision Transformer for Visual Recognition(在视觉transformer中为视觉识别指定协同上下文)
paper:https://arxiv.org/abs/2111.12994
code:https://github.com/TencentYoutuResearch/VisualRecognition-NomMer
MLP
[1] Dynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information(利用地理和时间信息进行细粒度图像分类的动态 MLP)
paper:https://arxiv.org/abs/2203.03253
code:https://github.com/ylingfeng/DynamicMLP.git
[2] Revisiting the Transferability of Supervised Pretraining: an MLP Perspective(重新审视监督预训练的可迁移性:MLP 视角)
paper:https://arxiv.org/abs/2112.00496
神经网络架构搜索
[1] Global Convergence of MAML and Theory-Inspired Neural Architecture Search for Few-Shot Learning(MAML 的全局收敛和受理论启发的神经架构搜索以进行 Few-Shot 学习)
paper:https://arxiv.org/abs/2203.09137
code:https://github.com/YiteWang/MetaNTK-NAS
07 人体解析/人体姿态估计
[1] Capturing Humans in Motion: Temporal-Attentive 3D Human Pose and Shape Estimation from Monocular Video(捕捉运动中的人类:来自单目视频的时间注意 3D 人体姿势和形状估计)
paper:https://arxiv.org/abs/2203.08534
video:https://mps-net.github.io/MPS-Net/
[2] Physical Inertial Poser (PIP): Physics-aware Real-time Human Motion Tracking from Sparse Inertial Sensors(来自稀疏惯性传感器的物理感知实时人体运动跟踪)
paper:https://arxiv.org/abs/2203.08528
project:https://xinyu-yi.github.io/PIP/
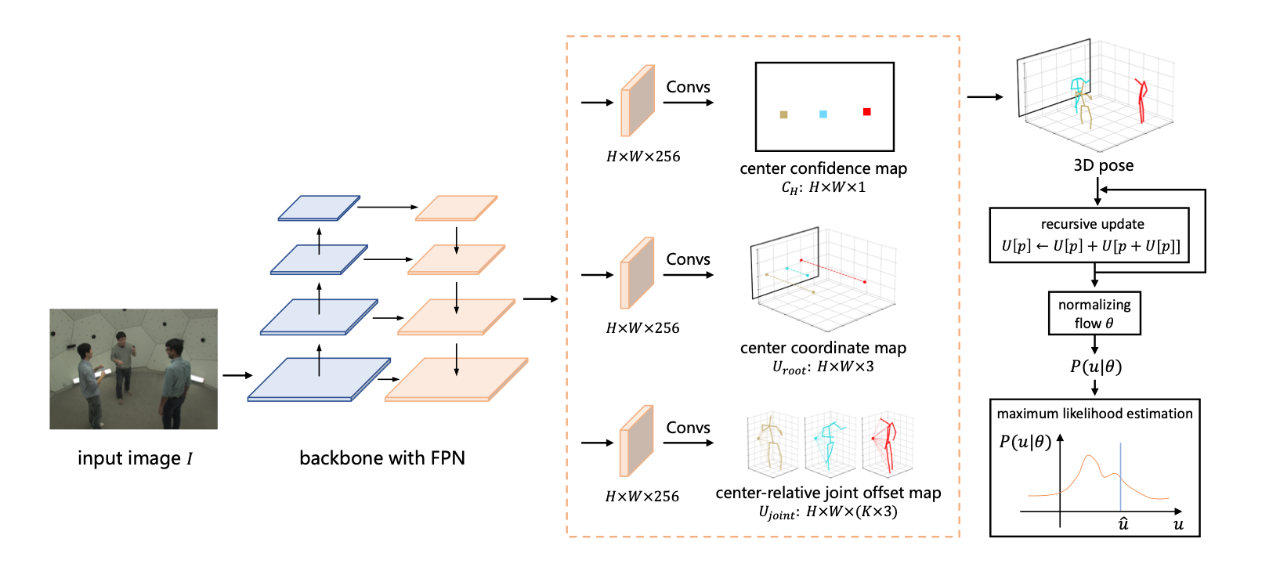
[3] Distribution-Aware Single-Stage Models for Multi-Person 3D Pose Estimation(用于多人 3D 姿势估计的分布感知单阶段模型)
paper:https://arxiv.org/abs/2203.07697
[4] MHFormer: Multi-Hypothesis Transformer for 3D Human Pose Estimation(用于 3D 人体姿势估计的多假设transformer)
paper:https://arxiv.org/abs/2111.12707
code:https://github.com/Vegetebird/MHFormer
[5] CDGNet: Class Distribution Guided Network for Human Parsing(用于人体解析的类分布引导网络)
paper:https://arxiv.org/abs/2111.14173
08 动作识别/检测
[1] Spatio-temporal Relation Modeling for Few-shot Action Recognition(小样本动作识别的时空关系建模)
paper:https://arxiv.org/abs/2112.05132
code:https://github.com/Anirudh257/strm
[2] RCL: Recurrent Continuous Localization for Temporal Action Detection(用于时间动作检测的循环连续定位)
paper:https://arxiv.org/abs/2203.07112
09 视觉定位/位姿估计
[1] ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation(用于 6DoF 对象姿态估计的粗到细表面编码)
paper:https://arxiv.org/abs/2203.09418
[2] Object Localization under Single Coarse Point Supervision(单粗点监督下的目标定位)
paper:https://arxiv.org/abs/2203.09338
code:https://github.com/ucas-vg/PointTinyBenchmark/
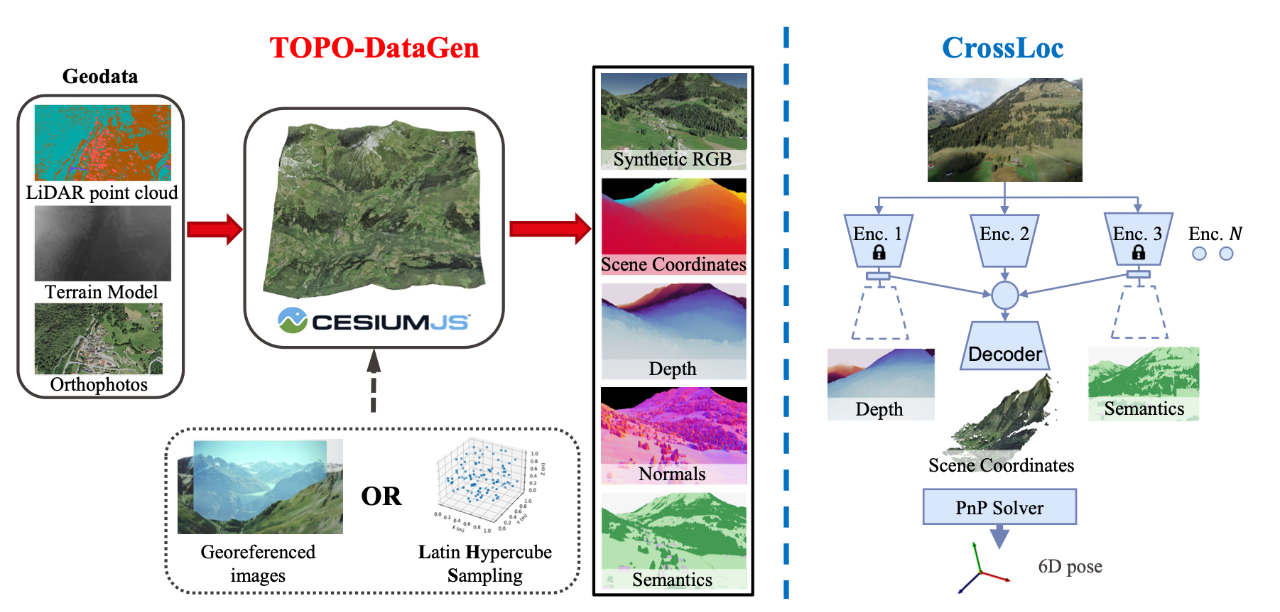
[3] CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data(多模式合成数据辅助的可扩展空中定位)
paper:https://arxiv.org/abs/2112.09081
code:https://github.com/TOPO-EPFL/CrossLoc
10 光流/运动估计
[1] GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting(通过几何引导的逐点投票进行类别级对象位姿估计)
paper:https://arxiv.org/abs/2203.07918
code:https://github.com/lolrudy/GPV_Pose
11 医学影像
[1] Vox2Cortex: Fast Explicit Reconstruction of Cortical Surfaces from 3D MRI Scans with Geometric Deep Neural Networks(使用几何深度神经网络从 3D MRI 扫描中快速显式重建皮质表面)
paper:https://arxiv.org/abs/2203.09446
code:https://github.com/ai-med/Vox2Cortex
[2] Generalizable Cross-modality Medical Image Segmentation via Style Augmentation and Dual Normalization(通过风格增强和双重归一化的可泛化跨模态医学图像分割)
paper:https://arxiv.org/abs/2112.11177
code:https://github.com/zzzqzhou/Dual-Normalization
12 文本理解
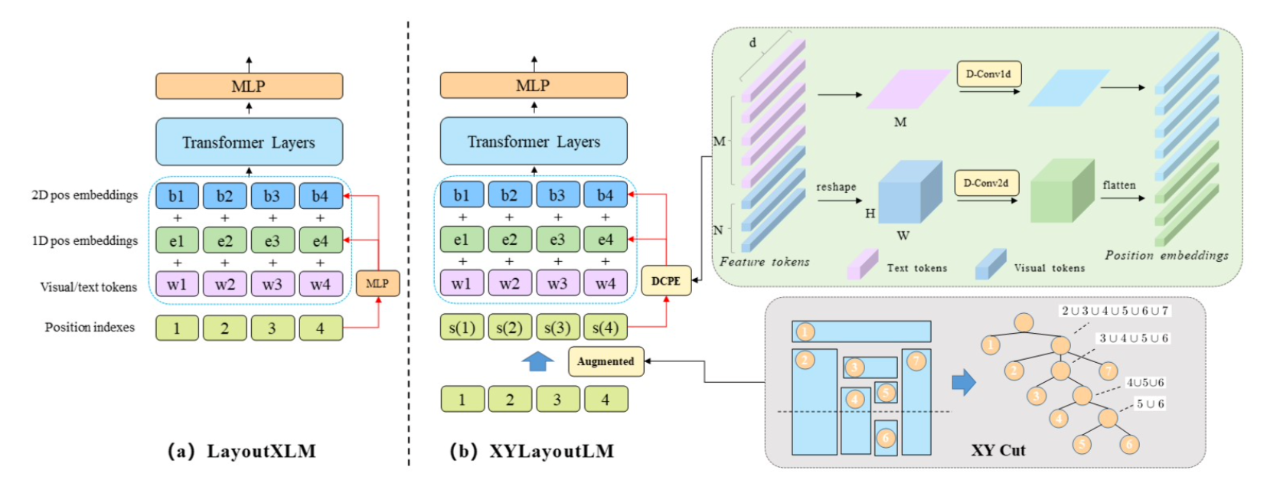
[1] XYLayoutLM: Towards Layout-Aware Multimodal Networks For Visually-Rich Document Understanding(迈向布局感知多模式网络,以实现视觉丰富的文档理解)
paper:https://arxiv.org/abs/2203.06947
13 GAN/生成式/对抗式
[1] Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input(通过基于对象的多样化输入提高目标对抗样本的可迁移性)
paper:https://arxiv.org/abs/2203.09123
code:https://github.com/dreamflake/ODI
[2] Towards Practical Certifiable Patch Defense with Vision Transformer(使用 Vision Transformer 实现实用的可认证补丁防御)
paper:https://arxiv.org/abs/2203.08519)
[3] Few Shot Generative Model Adaption via Relaxed Spatial Structural Alignment(基于松弛空间结构对齐的小样本生成模型自适应)
paper:https://arxiv.org/abs/2203.04121
[4] Enhancing Adversarial Training with Second-Order Statistics of Weights(使用权重的二阶统计加强对抗训练)
paper:https://arxiv.org/abs/2203.06020
code:https://github.com/Alexkael/S2O
14 视频检索
[1] Bridging Video-text Retrieval with Multiple Choice Questions(桥接视频文本检索与多项选择题)
paper:https://arxiv.org/abs/2201.04850
code:https://github.com/TencentARC/MCQ
15 图像&视频生成/合成
[1] Modulated Contrast for Versatile Image Synthesis(用于多功能图像合成的调制对比度)
paper:https://arxiv.org/abs/2203.09333
code:https://github.com/fnzhan/MoNCE
[2] Attribute Group Editing for Reliable Few-shot Image Generation(属性组编辑用于可靠的小样本图像生成)
paper:https://arxiv.org/abs/2203.08422
code:https://github.com/UniBester/AGE
[3] Text to Image Generation with Semantic-Spatial Aware GAN(使用语义空间感知 GAN 生成文本到图像)
paper:https://arxiv.org/abs/2104.00567
code:https://github.com/wtliao/text2image
[4] Playable Environments: Video Manipulation in Space and Time(可播放环境:空间和时间的视频操作)
paper:https://arxiv.org/abs/2203.01914
code:https://willi-menapace.github.io/playable-environments-website
[5] Depth-Aware Generative Adversarial Network for Talking Head Video Generation(用于说话头视频生成的深度感知生成对抗网络)
paper:https://arxiv.org/abs/2203.06605
code:https://github.com/harlanhong/CVPR2022-DaGAN
[6] FLAG: Flow-based 3D Avatar Generation from Sparse Observations(从稀疏观察中生成基于流的 3D 头像)
paper:https://arxiv.org/abs/2203.05789
project:https://microsoft.github.io/flag
16 视觉推理/视觉问答
[1] MuKEA: Multimodal Knowledge Extraction and Accumulation for Knowledge-based Visual Question Answering(基于知识的视觉问答的多模态知识提取与积累)
paper:https://arxiv.org/abs/2203.09138
code:https://github.com/AndersonStra/MuKEA
[2] REX: Reasoning-aware and Grounded Explanation(推理意识和扎根的解释)
paper:https://arxiv.org/abs/2203.06107
code:https://github.com/szzexpoi/rex
17 视觉预测
[1] On Adversarial Robustness of Trajectory Prediction for Autonomous Vehicles(自动驾驶汽车轨迹预测的对抗鲁棒性)
paper:https://arxiv.org/abs/2201.05057
code:https://github.com/zqzqz/AdvTrajectoryPrediction
18 图像计数
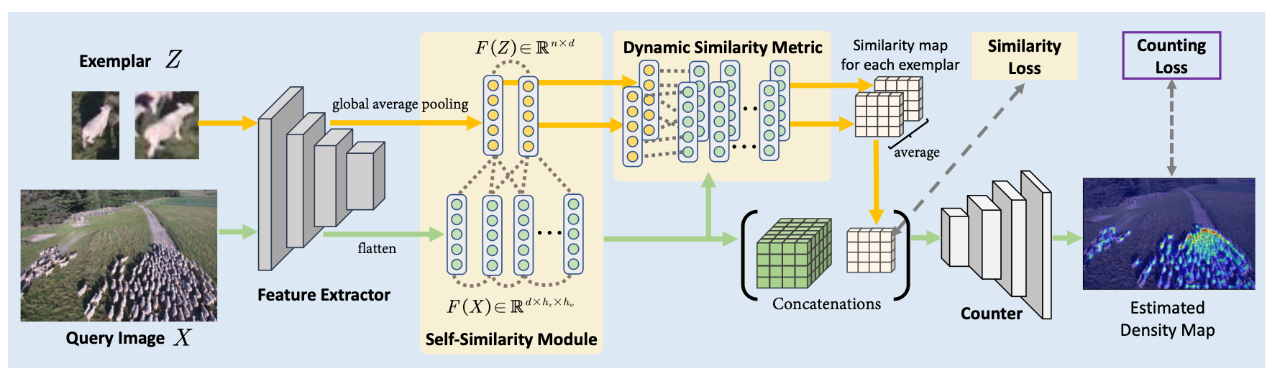
[1] Represent, Compare, and Learn: A Similarity-Aware Framework for Class-Agnostic Counting(表示、比较和学习:用于类不可知计数的相似性感知框架)
paper:https://arxiv.org/abs/2203.08354
code:https://github.com/flyinglynx/Bilinear-Matching-Network
19 机器人
[1] Coarse-to-Fine Q-attention: Efficient Learning for Visual Robotic Manipulation via Discretisation(通过离散化实现视觉机器人操作的高效学习)
paper:https://arxiv.org/abs/2106.12534
code:https://github.com/stepjam/ARM
project:https://sites.google.com/view/c2f-q-attention
20 多模态学习
[1] MERLOT Reserve: Neural Script Knowledge through Vision and Language and Sound(通过视觉、语言和声音的神经脚本知识)
paper:https://arxiv.org/abs/2201.02639
project:https://rowanzellers.com/merlotreserve
视觉-语言
[1] Pseudo-Q: Generating Pseudo Language Queries for Visual Grounding(为视觉基础生成伪语言查询)
paper:https://arxiv.org/abs/2203.08481
code:https://github.com/LeapLabTHU/Pseudo-Q
21 自监督/半监督/无监督学习
[1] SimMatch: Semi-supervised Learning with Similarity Matching(具有相似性匹配的半监督学习)
paper:https://arxiv.org/abs/2203.06915
code:https://github.com/KyleZheng1997/simmatch
[2] Robust Equivariant Imaging: a fully unsupervised framework for learning to image from noisy and partial measurements(一个完全无监督的框架,用于从噪声和部分测量中学习图像)
paper:https://arxiv.org/abs/2111.12855
code:https://github.com/edongdongchen/REI
[3] UniVIP: A Unified Framework for Self-Supervised Visual Pre-training(自监督视觉预训练的统一框架)
paper:https://arxiv.org/abs/2203.06965
22 联邦学习
[1] Fine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning(通过非 IID 联邦学习的无数据知识蒸馏微调全局模型)
paper:https://arxiv.org/abs/2203.09249
23 度量学习
[1] Non-isotropy Regularization for Proxy-based Deep Metric Learning(基于代理的深度度量学习的非各向同性正则化)
paper:https://arxiv.org/abs/2203.08547
code:https://github.com/ExplainableML/NonIsotropicProxyDML
[2] Integrating Language Guidance into Vision-based Deep Metric Learning(将语言指导集成到基于视觉的深度度量学习中)
paper:https://arxiv.org/abs/2203.08543
code:https://github.com/ExplainableML/LanguageGuidance_for_DML
24 增量学习
[1] Forward Compatible Few-Shot Class-Incremental Learning(前后兼容的小样本类增量学习)
paper:https://arxiv.org/abs/2203.06953
code:https://github.com/zhoudw-zdw/CVPR22-Fact
[2] Self-Sustaining Representation Expansion for Non-Exemplar Class-Incremental Learning(非示例类增量学习的自我维持表示扩展)
paper:https://arxiv.org/abs/2203.06359
25 迁移学习/domain/自适应
[1] Category Contrast for Unsupervised Domain Adaptation in Visual Tasks(视觉任务中无监督域适应的类别对比)
paper:https://arxiv.org/abs/2106.02885
[2] Learning Distinctive Margin toward Active Domain Adaptation(向主动领域适应学习独特的边际)
paper:https://arxiv.org/abs/2203.05738
code:https://github.com/TencentYoutuResearch/ActiveLearning-SDM
26 对比学习
[1] Rethinking Minimal Sufficient Representation in Contrastive Learning(重新思考对比学习中的最小充分表示)
paper:https://arxiv.org/abs/2203.07004
code:https://github.com/Haoqing-Wang/InfoCL
27 主动学习
[1] Active Learning by Feature Mixing(通过特征混合进行主动学习)
paper:https://arxiv.org/abs/2203.07034
code:https://github.com/Haoqing-Wang/InfoCL
28 数据处理
图像压缩
[1] The Devil Is in the Details: Window-based Attention for Image Compression(细节中的魔鬼:图像压缩的基于窗口的注意力)
paper:https://arxiv.org/abs/2203.08450
code:https://github.com/Googolxx/STF
图像聚类
[1] RAMA: A Rapid Multicut Algorithm on GPU(GPU 上的快速多切算法)
paper:https://arxiv.org/abs/2109.01838
code:https://github.com/pawelswoboda/RAMA
29 视觉表征学习
[1] Exploring Set Similarity for Dense Self-supervised Representation Learning(探索密集自监督表示学习的集合相似性)
paper:https://arxiv.org/abs/2107.08712
[2] Motion-aware Contrastive Video Representation Learning via Foreground-background Merging(通过前景-背景合并的运动感知对比视频表示学习)
paper:https://arxiv.org/abs/2109.15130
code:https://github.com/Mark12Ding/FAME
30 模型训练/泛化
[1] Can Neural Nets Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary Perspective(神经网络可以两次学习相同的模型吗?从决策边界的角度研究可重复性和双重下降)
paper:https://arxiv.org/abs/2203.08124
code:https://github.com/somepago/dbViz
31 噪声标签
[1] Scalable Penalized Regression for Noise Detection in Learning with Noisy Labels
paper:https://arxiv.org/abs/2203.07788
code:https://github.com/Yikai-Wang/SPR-LNL
32 模型压缩
知识蒸馏
[1] Decoupled Knowledge Distillation(解耦知识蒸馏)
paper:https://arxiv.org/abs/2203.08679
code:https://github.com/megvii-research/mdistiller
[2] Wavelet Knowledge Distillation: Towards Efficient Image-to-Image Translation(小波知识蒸馏:迈向高效的图像到图像转换)
paper:https://arxiv.org/abs/2203.06321
剪枝
[1] Interspace Pruning: Using Adaptive Filter Representations to Improve Training of Sparse CNNs(空间剪枝:使用自适应滤波器表示来改进稀疏 CNN 的训练)
paper:https://arxiv.org/abs/2203.07808
量化
[1] Implicit Feature Decoupling with Depthwise Quantization(使用深度量化的隐式特征解耦)
paper:https://arxiv.org/abs/2203.08080
33 数据集
[1] FERV39k: A Large-Scale Multi-Scene Dataset for Facial Expression Recognition in Videos(用于视频中面部表情识别的大规模多场景数据集)
paper:https://arxiv.org/abs/2203.09463

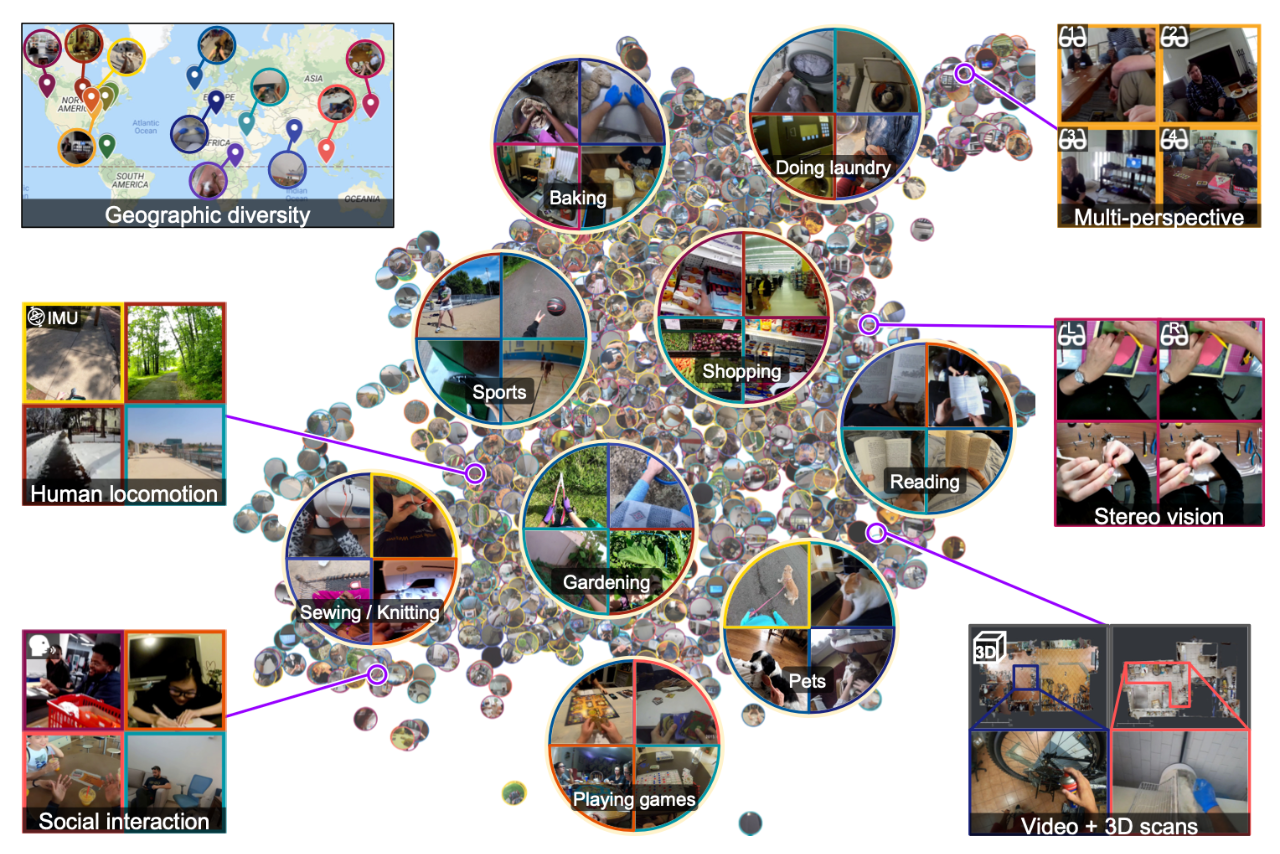
[2] Ego4D: Around the World in 3,000 Hours of Egocentric Video(3000 小时以自我为中心的视频环游世界)
paper:https://arxiv.org/abs/2110.07058
project:https://ego4d-data.org/
34 其他
[1] FastDOG: Fast Discrete Optimization on GPU(GPU 上的快速离散优化)
paper:https://arxiv.org/abs/2111.10270
code:https://github.com/LPMP/BDD
[2] AirObject: A Temporally Evolving Graph Embedding for Object Identification(用于对象识别的时间演化图嵌入)(object encoding)
paper:https://arxiv.org/abs/2111.15150
code:https://github.com/Nik-V9/AirObject
以上论文下载地址:https://bbs.cvmart.net/articles/6192
来源:极市平台
