百度王海峰详解全球首个知识增强千亿大模型——鹏城-百度·文心
发布时间:2021-12-15作为当前人工智能(AI)发展的重要方向,预训练模型已成为AI领域的技术新高地。
12月8日,鹏城实验室与百度联合召开发布会,正式发布双方共同研发的全球首个知识增强千亿大模型——鹏城-百度•文心(模型版本号:ERNIE 3.0 Titan)。该模型参数规模达到2600亿,已在60多项任务中取得“最好效果”。 中国工程院院士、鹏城实验室主任高文(左),百度首席技术官王海峰联合发布鹏城-百度·文心
中国工程院院士、鹏城实验室主任高文(左),百度首席技术官王海峰联合发布鹏城-百度·文心
中国工程院院士、鹏城实验室主任高文表示:“预训练模型对整个科学的发展、社会的发展、创新的发展都是非常重要的工具。运用这个工具,可以帮助做很多人工智能的赋能,不局限于某个领域,这对人工智能的发展是一个福音。”
“百度知识增强大模型从大规模知识和海量数据中融合学习,效率更高、效果更好,具有良好的可解释性。”百度首席技术官王海峰介绍。此次发布的鹏城-百度•文心是“全球首个知识增强千亿大模型”,在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果,并在30余项小样本和零样本任务上刷新基准。
作为“全球首个知识增强千亿大模型”, 鹏城-百度•文心有何特点?AI大模型如何应用落地?对此,王海峰接受了《中国科学报》的采访。
首个知识增强千亿大模型,鹏城-百度•文心知多少
▲ 《中国科学报》:如今大模型大行其道,鹏城实验室与百度共同研发的鹏城-百度•文心有哪些独特之处?
▲ 王海峰:
该模型是全球首个知识增强千亿大模型,也是目前为止全球最大的中文单体模型,参数规模达到2600亿。
在算法框架上,该模型沿用ERNIE 3.0的海量无监督文本与大规模知识图谱的平行预训练算法,模型结构上使用兼顾语言理解与语言生成的统一预训练框架。为提升模型语言理解与生成能力,研究团队进一步设计了可控和可信学习算法。
在训练上,结合百度飞桨自适应大规模分布式训练技术和“鹏城云脑Ⅱ”领先算力集群,解决了超大模型训练中的多个公认技术难题。在应用上,首创大模型在线蒸馏框架,大幅降低了大模型落地成本。
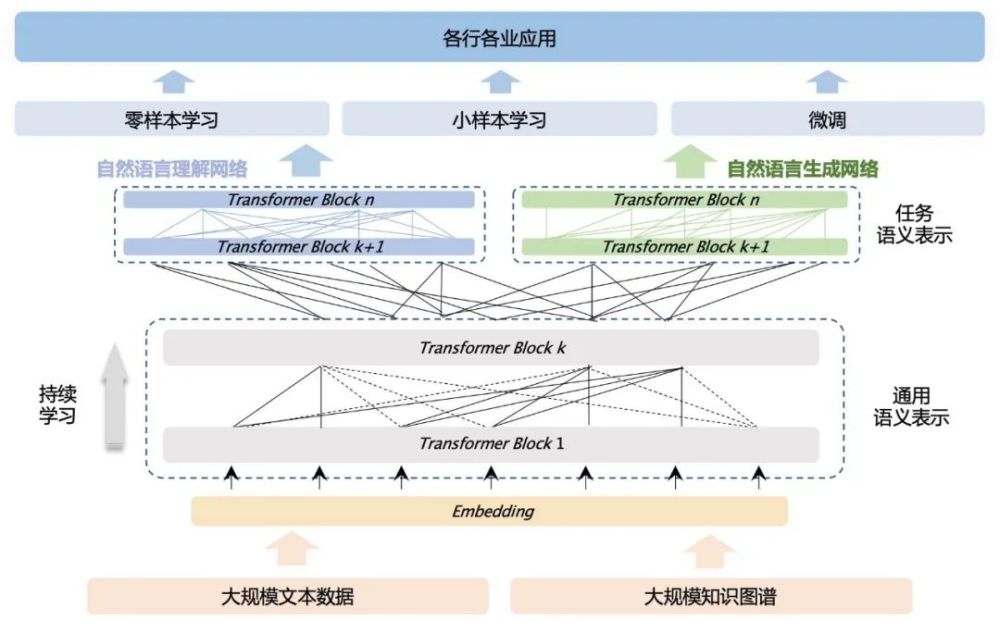
鹏城-百度·文心模型结构图
▲ 《中国科学报》:鹏城-百度•文心在具体训练任务中表现如何?
▲ 王海峰:
目前,该模型已在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果。
在大模型落地应用中,仅利用少量标注数据甚至无需标注数据,就能解决新场景的任务是AI工业大生产面临的关键问题。鹏城-百度•文心在30余项小样本和零样本任务上刷新基准,能够实现各类AI应用场景效果的提升,也为产业化规模应用打开了新窗口。
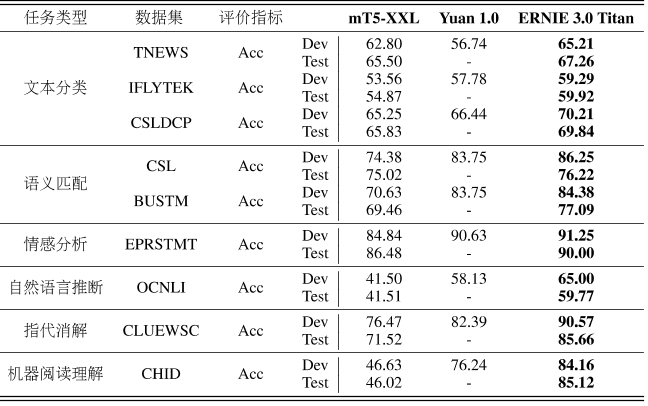
鹏城-百度·文心小样本学习效果
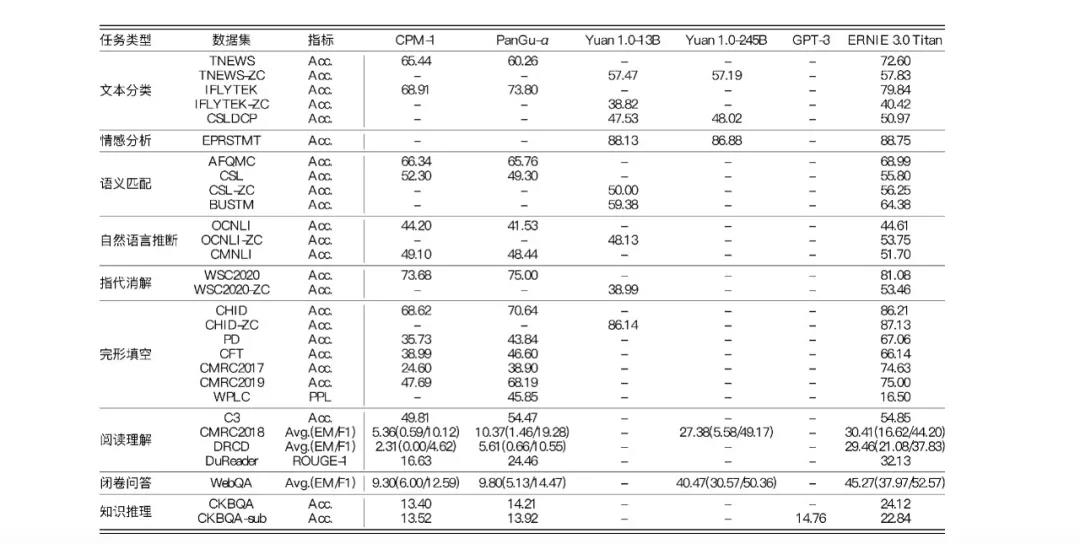
鹏城-百度·文心零样本学习效果
▲ 《中国科学报》:鹏城-百度•文心能有如此表现的背后,有哪些支撑加持?
▲ 王海峰:
鹏城-百度•文心的成功发布,得益于鹏城实验室的算力系统“鹏城云脑Ⅱ”和飞桨深度学习平台的强强联手,解决了超大模型训练的多个公认技术难题,使鹏城-百度•文心训练速度大幅提升,模型效果更优。
“鹏城云脑Ⅱ”是国产自主的首个E级AI算力平台,曾在国际上多个性能测试上获得冠军;飞桨是我国首个自主研发的深度学习开源开放平台,研制了端到端自适应分布式训练框架,实现多硬件支持,并行效率高达90%,有效支持鹏城-百度•文心千亿大模型高效、稳定地训练。
AI预训练模型,越大越好吗?
▲ 《中国科学报》:当前,巨量参数的大模型有成为AI领域新一轮“军备竞赛”的趋势,是否参数越大,就代表大模型效果越好?
▲ 王海峰:
大模型,大是一个相对的概念,可能会不断变得更大。我们也看到百度文心这几年的发展,随着参数量的增加,效果越来越好。但并非一味地追求参数规模大,大模型的效果就一定越来越好。或者说百度做大模型不是只考虑参数的大小。
百度文心大模型的核心特色和优势是知识增强。知识增强大模型从大规模知识和海量数据中融合学习,效率更高,效果更好,具有良好的可解释性。知识增强提升了模型的学习效率,能够在更小的参数规模下,取得更好的效果。
▲ 《中国科学报》:超大模型训练、推理需要消耗极其密集和昂贵的资源,因此应用落地成为难题。鹏城-百度•文心在实际应用落地中有何表现?
▲ 王海峰:
为解决大模型应用落地难题,百度团队首创了大模型在线蒸馏技术,模型参数压缩率可达99.98%,压缩版模型仅保留0.02%参数规模就能与原有模型效果相当,为产业大规模应用打开新窗口。
该技术在鹏城-百度•文心大模型学习的过程中周期性地将知识信号传递给若干个“学生模型”同时训练,达到蒸馏阶段一次性产出多尺寸“学生模型”的目的。相对传统蒸馏技术,该技术极大节省了因大模型额外蒸馏计算以及多个学生的重复知识传递带来的算力消耗问题。
▲ 《中国科学报》:目前鹏城-百度•文心大模型有哪些应用落地案例?
▲ 王海峰:
鹏城-百度•文心大模型近期会在OpenI启智社区开源,依托鹏城云脑Ⅱ对外开放,有助于推动产学研协各方充分挖掘AI大模型的赋能能力,助力科技创新,推动产业发展。
百度文心产业级知识增强大模型已大规模应用于百度搜索、信息流、智能音箱等互联网产品,并通过百度智能云赋能工业、能源、金融、通信、媒体、教育等各行各业。
以金融、保险等行业的合同业务为例,对于任务繁重、人员紧张、工作强度大、准确性和及时性要求高的合同业务处理,人工处理面临着产能和效率的巨大挑战,且需要处理人员具备较高的专业性,企业需付出额外培训成本。
2020年起,百度与金融领域的客户联合共建了提供保险合同条款智能解析模型的定制化建模,实现保险合同文本的条款解析分类。通过百度文心大模型赋能,保险合同条款智能解析模型能够完成一份合同内近40个类目条款的智能分类,使得业务员处理单份合同文本的时长可缩短到1分钟,大大提升了工作效率。目前这套智能解析模型完成了上亿份合同条款的智能分类,实现了降本增效。
再比如,中国联通与百度合作,联手打造了集约化智慧客服,释放人力资源,降低人工成本,让服务更精准、工作更高效。以文心大模型强大的语义表示能力为基础,打造面向对话理解问题的专用预训练模型,从而实现了一套面向场景可定制的对话技术。在保持优异应用效果的同时,该技术对数据标注量的需求降低45%以上,显著提升了智能客服业务拓展的效率。
来源:科学网
